In October, Antmicro announced the open hardware Jetson AGX Thor Baseboard for the latest addition to the Jetson series designed for demanding edge AI scenarios. To further accommodate the growing customer interest in building Thor-based products with Antmicro’s baseboard, featuring a Blackwell GPU-based SoM sporting up to 2560 CUDA and 96 Tensor cores and a 128 GB LPDDR5X memory, we have been testing Thor’s capabilities in terms of running state-of-the-art AI models.
Having employed our Kenning AI benchmarking, optimization, and deployment framework for an in-depth analysis of the hardware’s work, in this article we demonstrate the benchmark results and describe an example of how to deploy some of these models on the Jetson AGX Thor with the help of Kenning and ROS 2 to launch instance segmentation, pose estimation, and depth estimation simultaneously in real time.
Benchmarking and optimizing AI models through Kenning
Kenning optimizations and platform definition
To optimize and benchmark the selected AI models, and then to generate performance reports for them, we’ve used Kenning, our framework for deep neural network (DNN) applications that comes with an API agnostic to used frameworks, runtimes, and platforms. Kenning is a universal tool where different models can run on different hardware without re-writing large sections of code. You can also use it to create deployment flows, runtimes, and manage datasets.
The optimization is done through Kenning’s optimizers. Thanks to them, Kenning can process AI models, for example, by compiling them to another format, such as Open Neural Network Exchange (ONNX), LiteRT Flatbuffers, or libraries generated by either IREE or TVM.
To ease model compilation for the Jetson AGX Thor, we created a Kenning-specific definition for the platform. The definition is a set of all necessary metadata and compilation guidelines for runtimes, so that you don’t have to write compilation flags, device constraints with regard to memory, compute capability, and other parameters explicitly for Kenning scenarios. As a result, everything boils down to defining the following:
platform:
type: CUDAPlatform
parameters:
name: jetson_thor_devkit
dataset:
type: PetDataset
parameters:
dataset_root: ./build/PetDataset
model_wrapper:
type: TensorFlowPetDatasetMobileNetV2
parameters:
model_path: kenning:///models/classification/tensorflow_pet_dataset_mobilenetv2.h5
optimizers:
- type: kenning.optimizers.tvm.TVMCompiler
parameters:
model_framework: keras
compiled_model_path: ./build/compiled-model.tarAI models and benchmark results
For testing purposes, we selected three small sets of AI models and four large ones. The former includes DINOv2, YOLACT, and MMPose, whereas the latter consists of text-to-image models, Segment-Anything-Models (SAM), and gpt-oss-120b.
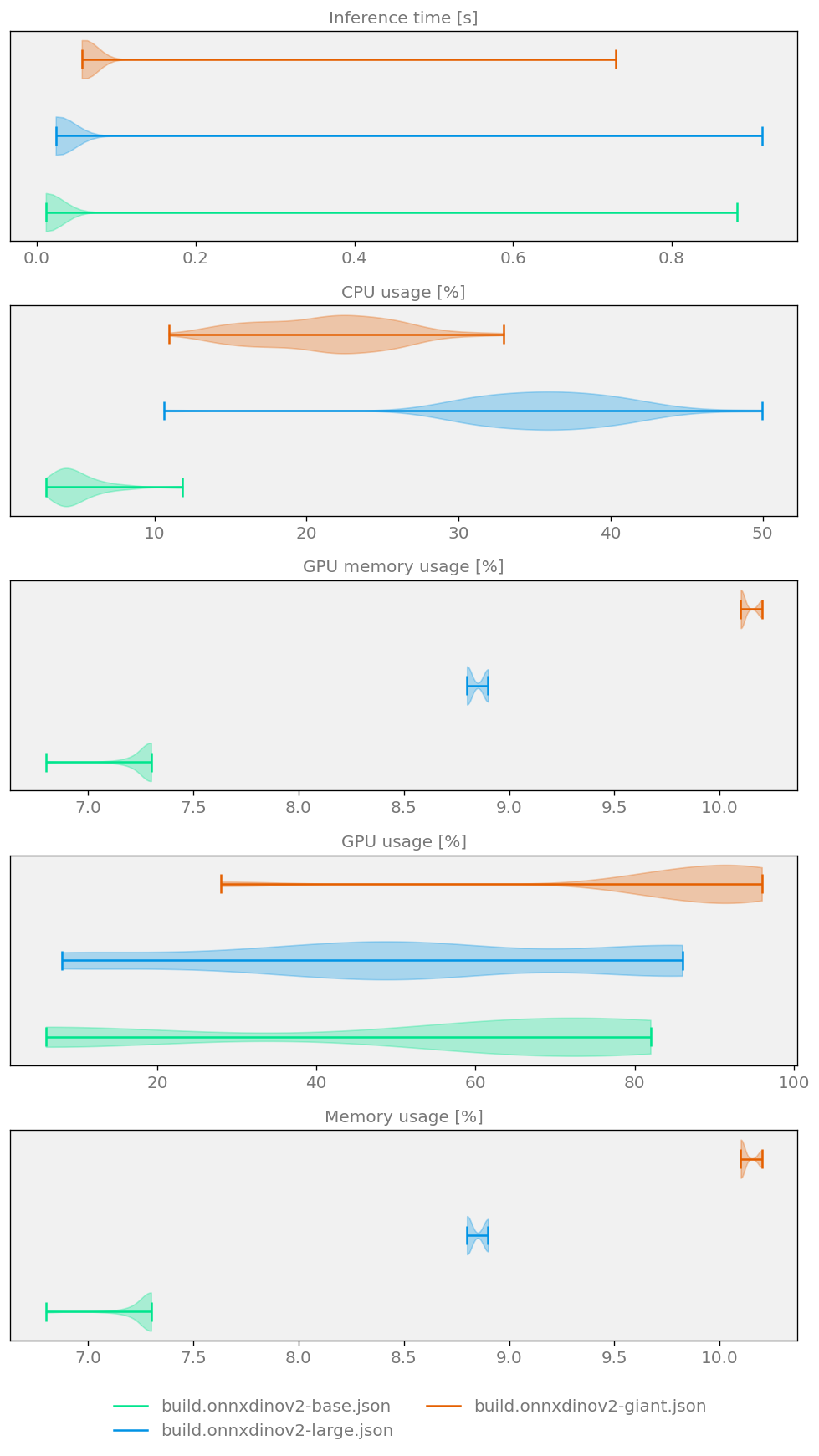
DINOv2 is a set of models producing visual features that can be employed for a variety of computer vision tasks. The models are useful in different areas, and their results don’t require additional adjustments. DINOv2 was trained on 142 million unannotated images. In the present study, we used it for depth estimation.
We used Kenning to convert DINOv2 models to ONNX and execute them with the ONNX Runtime as an inference library. You can see the benchmark results below, where we tested the base, large, and giant DINOv2 variants:
YOLACT is a convolutional neural network model that detects and segments objects of supported types in an image in real time. It creates bounding boxes encapsulating the detected objects, defines masks within those boxes, creating cut-offs of the objects, and provides the probability of the objects’ detected classes.
MMPose is an open source set of tools and models for estimating human poses. For selected MMPose models, we used the outputs from YOLACT to find people in the camera frame and provided the frame parts with detected people to the MMPose model to generate their poses.
We tested MMPose’s PyTorch and ONNX Runtime variants. You can see their respective performance results below:
| Model format | Avg CPU memory usage (%) | Avg CPU usage (%) | Avg GPU memory usage (%) | Avg GPU usage (%) | Total inference time (s) |
|---|---|---|---|---|---|
| PyTorch | 77 | 8 | 0.77 | 15 | 8.12 |
| ONNX Runtime | 9 | 13 | 0.10 | 18 | 3.34 |
The first larger models that we tested were text-to-image models, which produce high-quality images based on a provided prompt. We tested Stable Diffusion XL Base 1.0 and FLUX.1 Schnell, with the former focusing on photorealistic output through shorter prompts, and the latter on fast generation in a few steps. They yielded the following results, with iterations referring to consecutive data batches:
| Model name | RAM used (GB) | Total inference time (s) | Time per iteration (s) |
|---|---|---|---|
| Stable Diffusion XL Base 1.0 | 12 | 15 | 0.3 |
| FLUX.1 Schnell | 37 | 96 | 1.92 |
Next, we tested SAM - extendable, transformer-based models developed by Meta that can segment various objects in an image in three manners:
- With an exemplar: we deliver a sample object that we wish to extract from the image.
- With markers or coordinates: we point to the objects that we wish to extract from the image.
- With a whole scene: a scene is segmented into distinguishable objects of any type.
Specifically, three SAM versions were tested:
- SAM 1: the basic model that comes in three variants - SAM ViT Base, SAM ViT Large, and SAM ViT Huge.
- SAM 2: a model that extends the object segmentation functionality to video processing and comes in four variants - SAM 2.1 Hiera Tiny, SAM 2.1 Hiera Small, SAM 2.1 Hiera Base+, and SAM 2.1 Hiera Large.
- Fast SAM: a model that was trained on a small percentage of the original SAM data. It provides similar results to SAM 1 while being faster.
The table below presents the test results of the three SAM versions and their variants:
| Variant name | RAM usage (GB) | Total inference time (s) |
|---|---|---|
| Fast SAM | 2.0 | 0.11 |
| SAM ViT Base | 1.8 | 5.16 |
| SAM ViT Large | 3.0 | 5.97 |
| SAM ViT Huge | 5.6 | 6.80 |
| SAM 2.1 Hiera Tiny | 1.8 | 3.82 |
| SAM 2.1 Hiera Small | 1.8 | 3.96 |
| SAM 2.1 Hiera Base+ | 1.8 | 3.95 |
| SAM 2.1 Hiera Large | 2.6 | 4.18 |
The last large model benchmarked in Kenning was gpt-oss-120b, an open source Large Language Model (LLM) released by OpenAI. It has a context window of 131072 tokens and reasoning mechanisms that enable processing massive documents and performing high-quality analysis. Because of its RAM consumption, this state-of-the-art LLM normally doesn’t fit into a single GPU, but Jetson AGX Thor’s 128 GB capacity allows loading an entire model without any special adjustments.
The model was launched using the llama.cpp runtime, and you can find the performance results below:
| Model name | Avg CPU memory usage (%) | Avg CPU usage (%) | Tokens per second |
|---|---|---|---|
| gpt-oss-120b | 62 | 15 | 9-21 |
As the collected data show, Jetson AGX Thor is able to work with and process various complex models efficiently. Thanks to massive resources, it can be successfully deployed in robotics, AI agents relying on LLMs, generative art, and complex computer vision pipelines.
What is more, Antmicro’s Kenning is able to optimize complex models and produce extensively detailed reports in an accessible and reproducible manner for this and other platforms.
To reproduce the experiments run on Jetson AGX Thor, check the already prepared configurations for the related DINOv2 and MMPose scripts, as well as others.
Running multiple models in parallel on Jetson AGX Thor
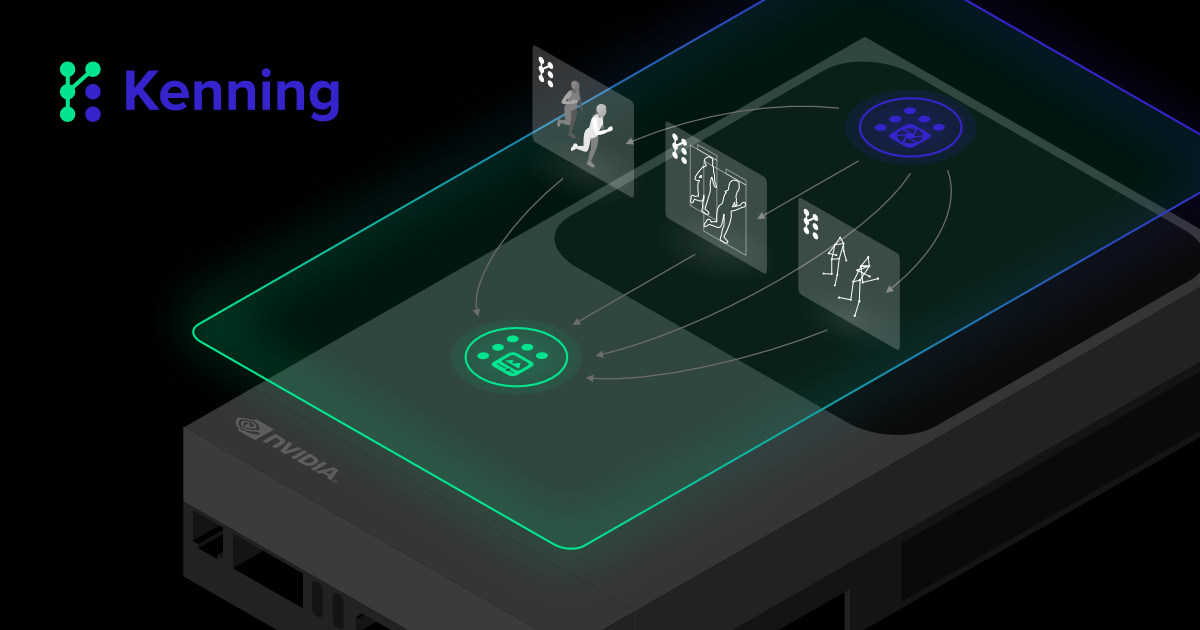
To further test and demonstrate Jetson AGX Thor’s capabilities, a demo is available on Antmicro’s GitHub in which we deployed YOLACT, MMPose, and DINOv2 running simultaneously and processing live feed from a camera.
The demo consists of a ROS 2 system of nodes where we run the following components:
- ROS 2 Camera Node: our implementation of the ROS 2 node controlling the camera and sending the frames to other nodes for use, with an easy-to-modify library to control a camera based on Video for Linux version 2 (V4L2).
- Recently improved ROS 2 integration in Kenning: enables us to run Kenning as a ROS 2 node to connect to the existing ROS 2 system and evaluate the performance of AI-enabled nodes, or to encapsulate models and expose them as services or topics to the rest of the ROS 2 nodes (deployment). We used the integration in the demo to create ROS 2 nodes for the following model scenarios:
- YOLACT scenario for instance segmentation
- MMPose scenario for pose estimation
- DINOv2 scenario for depth estimation
- GUI based on our ROS 2 GUI Node library: the library enables forming responsive, GPU-enabled visualizations of ROS 2 topics, services, actions, and more, easily.
Each ROS 2 node runs in an individual process, which could hinder performance due to time-sliced access to the GPU for individual processes. However, since the Ampere architecture, we can involve the Multi-Process Service (MPS) to mitigate this problem. The MPS is an alternative implementation of the CUDA API. The MPS architecture efficiently parallelizes multiple models on a single eGPU present in Thor thanks to the Hyper-Q technology, which enables CUDA kernels to be processed concurrently. This solution is beneficial when a single process doesn’t utilize the GPU to its full extent. The MPS negotiates access to GPU resources for several apps running in parallel, in non-exclusive mode, thus enabling us to use the full power of Jetson AGX Thor.
The prepared setup looks as follows:

You can watch the demo below:
For detailed information on launching the demo, follow its README.
Build and test complete AI products with Jetson AGX Thor Baseboard and Kenning
Antmicro’s Kenning framework greatly simplifies incorporating diverse hardware with varied AI options to arrive at an all-around solution for DNN deployment flows and runtimes. Provision your desired applications to optimize, test, and benchmark them seamlessly - just as we did benchmarking the AI models on Jetson AGX Thor. We can extend Kenning’s existing functionalities and provide commercial integration services to suit your needs.
Antmicro can help you develop your next high-performance edge AI product from hardware design to BSP and software and AI deployment. You can also check out our Jetson AGX Thor Baseboard in Antmicro’s System Designer. For any such services or others, simply contact us at contact@antmicro.com.


