Many of Antmicro’s commercial projects are based on the company’s open hardware boards for the NVIDIA Jetson ecosystem, with the NVIDIA Jetson Nano/Xavier NX baseboard leading the way as the most notable example. The most recent addition to the Jetson family, the AGX Orin series, introduces a significant performance increase for deep learning inference thanks to its Ampere GPU and Tensor Cores. An open source Jetson Orin Baseboard has been recently released by Antmicro, and you can read more about it in a dedicated blog note.
On top of commercial engagements, Antmicro is pursuing a number of R&D projects in open source AI, ASIC development and tooling and related areas, and our recent work in the Very Efficient Deep Learning for IoT project - or VEDLIoT in short - involved performance testing of popular Deep Neural Network models running on a variety of ASIC and FPGA platforms in terms of both realistically achievable quality and speed. With its recent introduction, the new AGX Orin platform became an obvious target for the research activity, and was tested using various models with a range of optimizations applied using Antmicro’s open source Kenning framework, built for that very purpose, i.e. model optimization, deployment and benchmarking at the edge.
The models tested include the ResNet50 and MobileNetV3 classification models, as well as the YOLOv4 object detection model, and this blog note will describe how to replicate the results using some of the new and exciting developments in Kenning such as model comparison reports, TVM quantization and model metadata serialization which we covered in more detail in a very recent note.

Running NVIDIA Jetson Orin benchmarks
NVIDIA Jetson AGX Orin is a very powerful edge AI platform, good for resource-heavy tasks relying on deep neural networks.
The most interesting specifications of the NVIDIA Jetson AGX Orin from the edge AI perspective are:
- 1792 Ampere CUDA cores,
- 56 Ampere Tensor cores,
- 2 NVIDIA DLA engines (NVDLA v2),
- 32GB of 256-bit LPDDR5 eGPU memory, shared between the CPU and the GPU,
- 8-core ARM Cortex-A78AE v8.2 64-bit.
With such capabilities, AGX Orin is capable of running:
- state-of-the art, very large deep neural networks,
- deep neural network on very large batches of data, allowing to process massive amounts of data in parallel,
- large, multi-node AI solutions consisting of multiple models, for advanced video, text, or audio processing purposes.
For the VEDLIoT work, Antmicro decided to try out various optimization techniques in Kenning with the use of such underlying frameworks as TensorFlow, PyTorch, ONNX, TensorFlow Lite and Apache TVM.
The ONNX framework was mainly used as an interface between the native framework (a framework in which the model was designed and trained, such as TensorFlow or PyTorch) and the above-mentioned compilers. TensorFlow Lite was used for initial optimizations as well as quantization of the network. TVM was used as the final framework, compiling a shared library containing a GPU-enabled implementation of the model.
TVM allows use of CUDA libraries, providing highly optimized implementations for neural network operations and general linear algebra, such as CUDNN and CUBLAS. It can even perform initial optimizations and then delegate the entire model execution to TensorRT, or at least the parts that are supported by this library.
During our experiments, we tried:
- various precisions for model activations and weights - FP32, FP16 and INT8,
- running models using CUDNN/CUBLAS libraries, running on pure CUDA kernels as well as with TensorRT delegation,
- altering model compilation flows,
- changing activation data layouts and convolutional kernels.
The last one is covered by TVM and from a Kenning configuration perspective, it is a matter of setting conv2d_data_layout and conv2d_kernel_layout fields to TVMCompiler Optimizer, i.e.:
{
"type": "kenning.compilers.tvm.TVMCompiler",
"parameters": {
"target": "cuda -arch=sm_87 -libs=cudnn,cublas",
"target_host": null,
"opt_level": 3,
"compile_use_vm": false,
"output_conversion_function": "default",
"compiled_model_path": "./build/resnet50-fp32.tar",
"conv2d_data_layout": "NHWC",
"conv2d_kernel_layout": "OHWI"
}
}All of the scripts used for optimizing ResNet50, MobileNetV3 and YOLOv4 are available in the JSON configuration scripts in the Kenning repository with filenames containing orin.
The experiments were executed with batch size equal to 1.
We have collected the most interesting results from the benchmarks listed above and visualized them using comparison reports in Kenning.
NVIDIA Jetson AGX Orin benchmarks for classifiers
Let us start with the classification models, that is ResNet50 and MobileNetV3. ResNet50 is an architecture from 2015 that has been widely adopted for various use cases, which consists of the most common supported layers in most deep learning frameworks. MobileNetV3, on the other hand, is a state-of-the-art small model for classification, consisting of one of the most recent activation functions and blocks. Due to this fact, not all optimizations were possible to apply on the latter model.
Model optimizations were performed using:
- TensorFlow Lite for initial model optimization and quantization for INT8 models,
- ONNX for migrating models from one optimization framework to another,
- Apache TVM for data layout transformation, optionally precision reduction to FP16 and final model compilation using GPU-enabled libraries (CUDNN with CUBLAS or TensorRT).
For ResNet50 we created CUDNN-enabled models with FP32, FP16 and INT8 precision, and TensorRT-enabled FP32 and FP16 models. For MobileNetV3 we created CUDNN-enabled models with FP32 and FP16 precision.
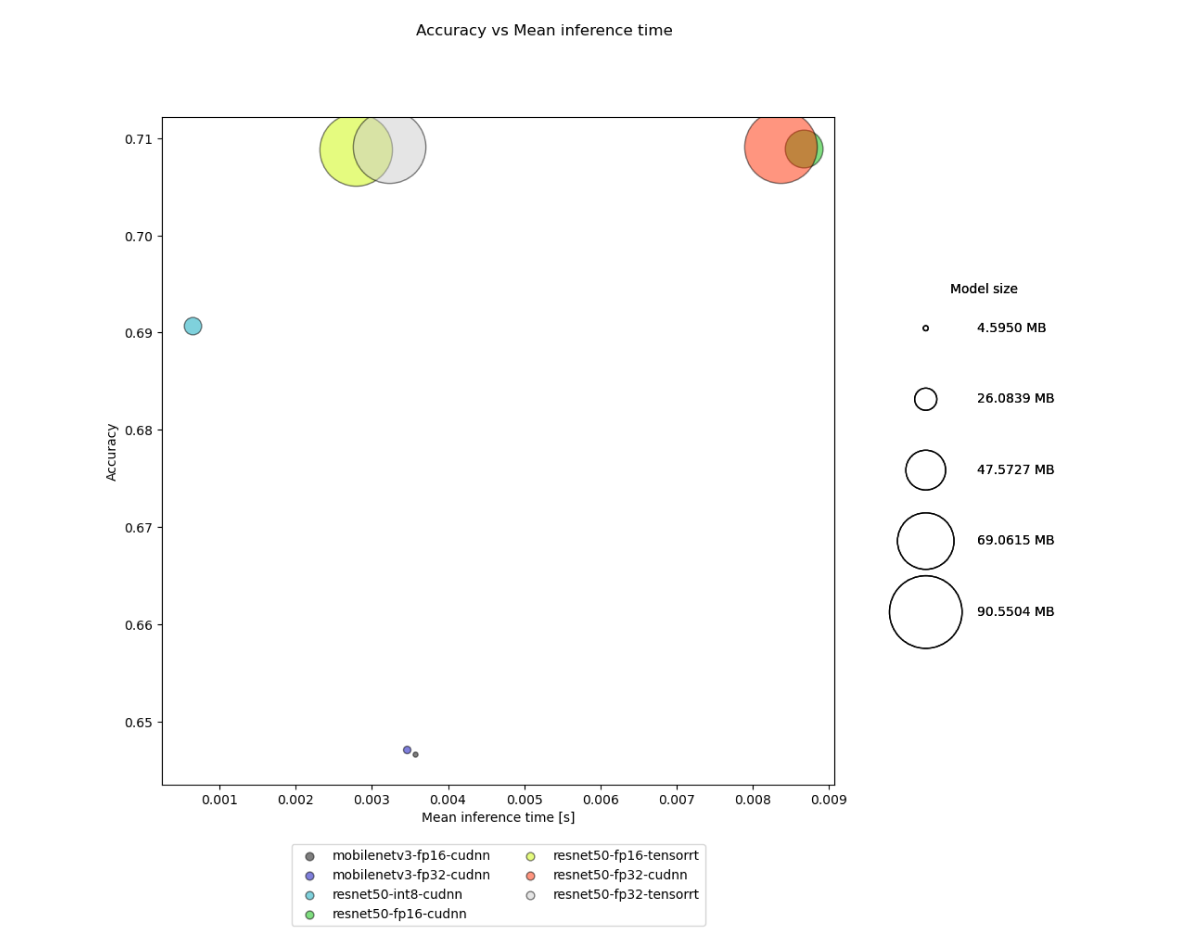
Let’s visualize the inference time, size and accuracy of the models:
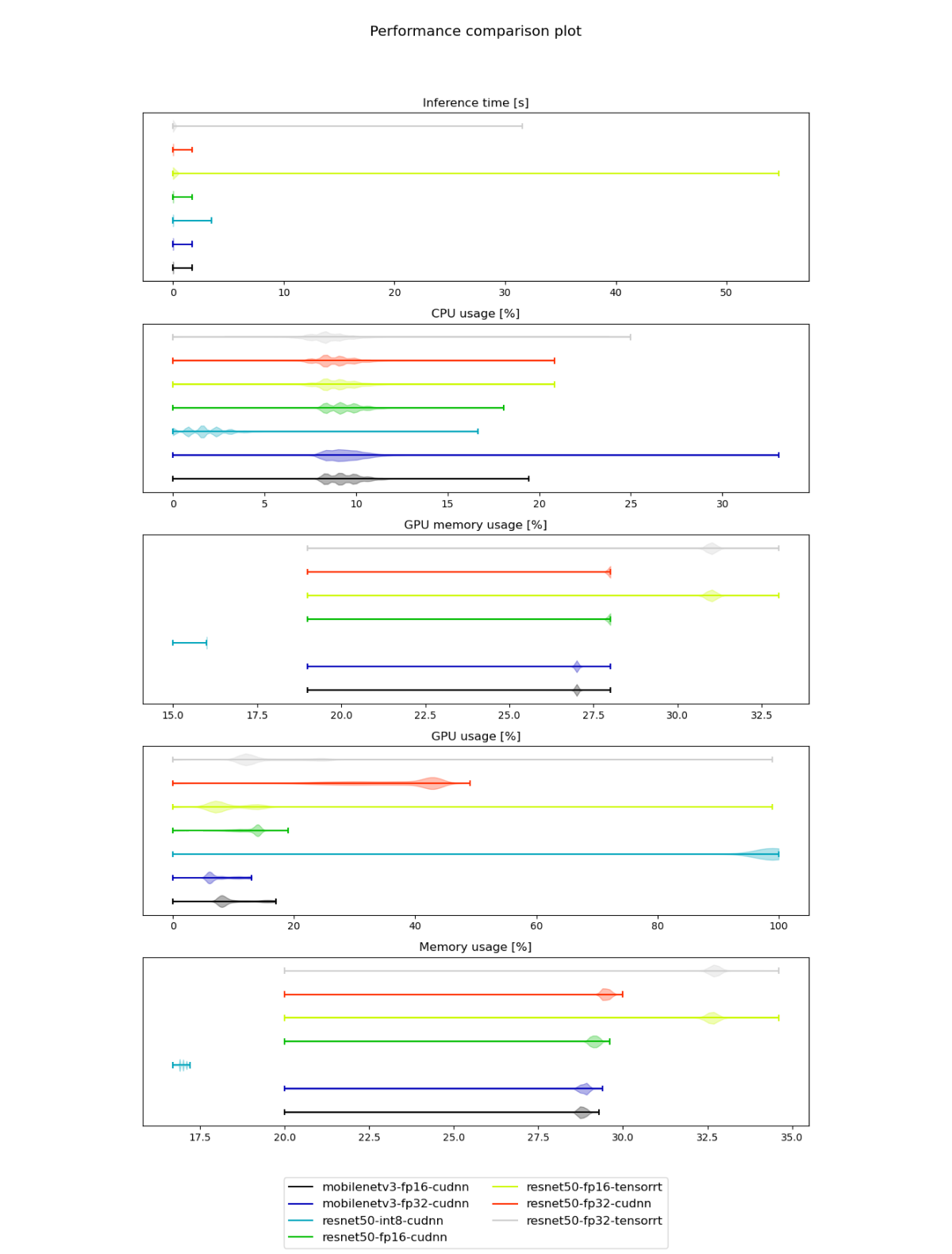
Next, let’s visualize the resource utilization for the models and inference time:
NVIDIA Jetson AGX Orin benchmarks for detectors
YOLOv4 was tested with FP32 and FP16 precisions, using CUDNN and TensorRT libraries.
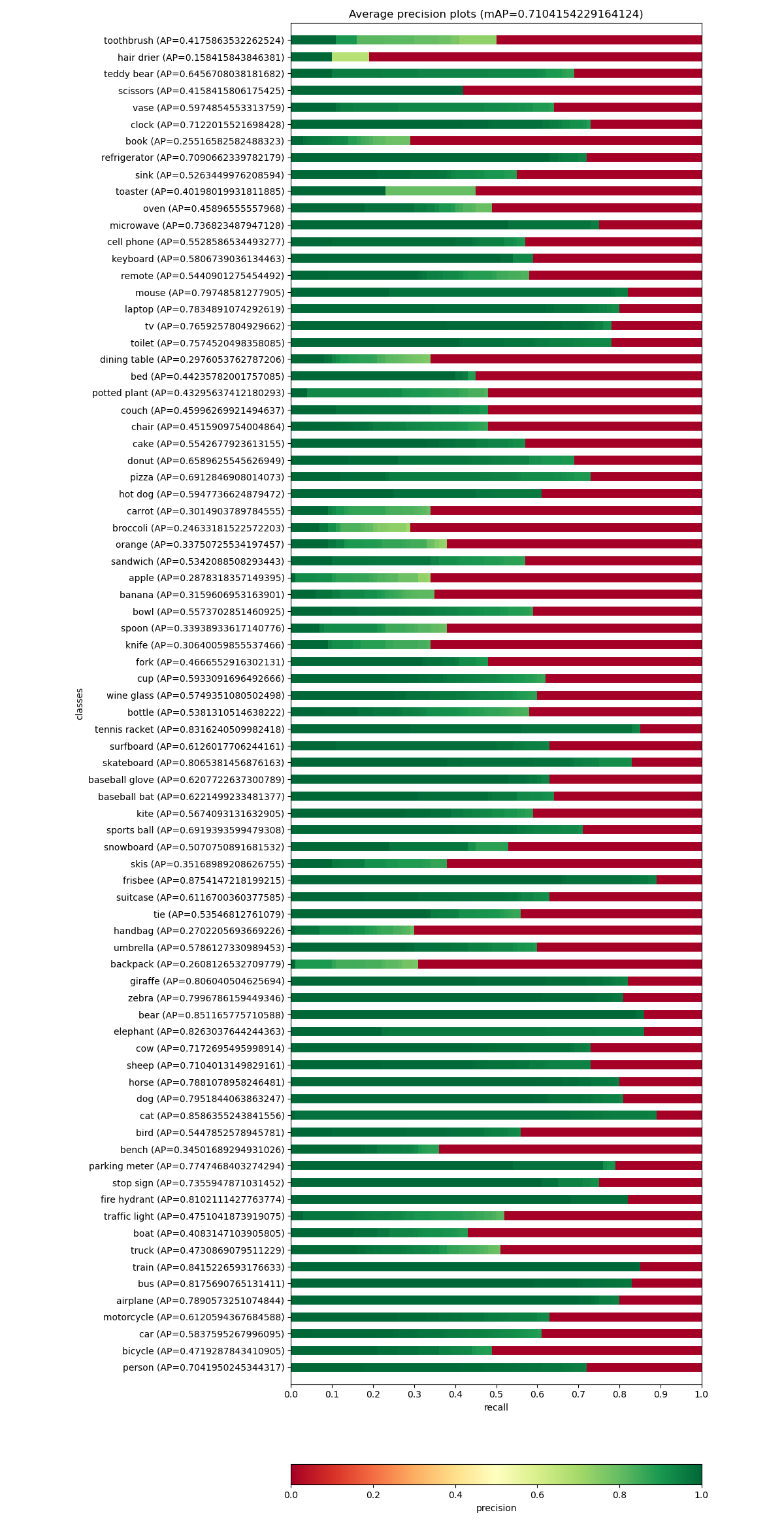
Let’s begin with recall-precision measurements and mean average precision (all 4 YOLOv4 combinations have the same quality):
Let’s now analyze the resource usage and inference time:

Performance summary
To sum up, the classification models performed as follows:

The detection models performed as follows:

As you can see, performance and quality improvements that depend on selected libraries and compilation flows are not always straightforward - interactions between models, optimization techniques and implementations of operations may result in unexpected quality degradation or performance issues that are not visible during model compilation, but rather during its evaluation on the target platform.
With Kenning, testing out various combinations of optimization and compilation frameworks is a matter of just a few lines of code. We could seamlessly take models from TensorFlow (for classification models) or PyTorch (for the YOLOv4 model, after parsing the original model implementation) and pass them through TensorFlow Lite and TVM optimization and compilation functions.
The most tedious part of the work, i.e. passing model shapes, model-specific parameters and I/O processing, both model and framework-specific, is handled under-the-hood in Kenning, leaving the user only with the need to tweak high-level parameters to get the most out of the model. With the recent introduction of comparison reports, analyzing improvements for particular models has become even easier - we can easily track optimization anomalies, quality degradation or excessive use of resources.
For Jetson AGX Orin, TensorRT-based TVM runtime may introduce some overhead in the beginning, as the model gets optimized on the fly during the first inference passes. However, it eventually significantly outperforms CUDNN-based implementations - for example for ResNet50 models processing time drops from 8-9ms per image down to 2-3ms depending on selected precision.
When it comes to quantization, not all models respond well to precision reduction to 8-bit integers - MobileNetV3 yields significantly worse results, regardless of the calibration dataset size. However, if the calibration process ends successfully, the model can get an outstanding boost with insignificant loss of quality, as can be observed again for the ResNet50 network - with preserved ~70% accuracy we get an almost 4 times smaller model, which processes a single image in ~0.6ms, the fastest among all tested classifiers. It even outperforms MobileNetV3 FP32 and FP16 models in terms of speed and quality while being quite small (4 times larger than MobileNetV3 variants).
With FP16 precision, the quality in most cases remains almost the same - it can be slightly worse or better than the original FP32 implementation. As for model size and inference time, the reductions there are framework-specific (TensorRT runtime has a better inference time, while CUDNN-based optimizations with TVM precision reduction results in a smaller model).
It is always recommended to test out various implementations and optimizations in order to find the best-fitting solution for a given application, as well as to check their performance and quality.
Simplified benchmarking with Kenning
Kenning can help you get traceable, easy-to-analyze reports that can be used to iteratively improve model runtimes on target hardware. As it supports multiple optimization and compilation frameworks (including TensorFlow Optimization Toolkit, TensorFlow Lite, Apache TVM, IREE and ONNX Runtime), adding new models and testing them on new hardware platforms is quite straightforward.
If you would like to get more out of your AI flows, Antmicro will gladly assist you in adapting and customizing Kenning to your needs. If you’re interested in utilizing Kenning’s capabilities for running, benchmarking and testing DNN models in your next project, make sure to reach out to us at contact@antmicro.com.


