Creating Machine Learning models for deployment on constrained devices requires a considerable number of manual tweaks. Developers need to take into account the size and compute constraints of the target platform to adjust the architecture, as well as search for optimal training hyperparameters. These include learning rate, regularizations, optimizer and its parameters, as well as datasets, optimal model compression configuration and more. The AI-specific expertise these steps require also makes model development a barrier for embedded system engineers.
In order to automate this process, together with Analog Devices, Inc (ADI), Antmicro introduced an AutoML module to Kenning, an open source AI optimization and deployment framework. Its flow lets you pick a dataset, a Neural Architecture Search configuration, and a target platform to produce models tailored to a specified problem and device in a fully automated manner. To wrap this functionality in an easy-to-use UI, we are also developing a VS Code plugin that runs AutoML tasks for a given application, dataset and platform. As a result, developers will be able to declare a time window for the module to search for the most optimized, bespoke configurations and be provided with several most promising results.

In the paragraphs below, you’ll learn more about the implementation and configuration of the module, how it helps automatically navigate through the massive configuration space of model training, and its reporting capabilities. We will also present and guide you through a demo scenario that Antmicro and ADI are showcasing at this year’s Embedded World in Nuremberg. The demo presents a use case of creating an anomaly detection model for sensory data in a time series targeted for the ADI MAX32690 MCU, which is then deployed and run on the physical MAX32690 device as well as on its digital twin simulated in Antmicro’s flagship open source simulation framework. AI model execution in the demo is handled using our AI model execution runtime for Zephyr RTOS - Kenning Zephyr Runtime.
Introducing AutoML pipelines in Kenning
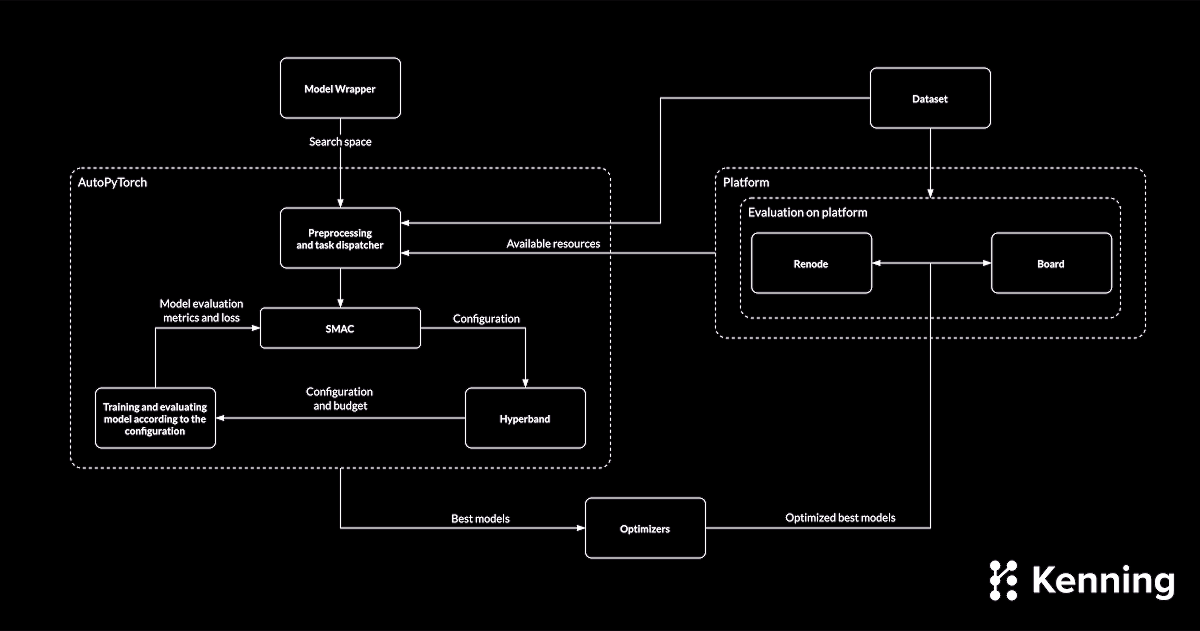
When looking for model candidates for a given platform and dataset, we need to define a search space within which our AutoML algorithm can look for the right configuration of the model and training pipeline. The provision of the search space is handled by implementations of the ModelWrapper class available in Kenning - the training parameters, as well as neural network architecture configuration can be provided using class parameters, along with allowed values and ranges.
With the search space prepared, the AutoML module searches through it in order to find the best fitting models for a given dataset, using the SMAC (Sequential Model-based Algorithm Configuration) which samples the search space in order to determine best-performing configurations. The algorithm uses samples that were already evaluated in terms of model configuration and training to create a probabilistic representation of the function (with Gaussian distributions) and chooses the next point (configuration) to evaluate. This choice can be assessed as a way towards one of two goals: minimizing the uncertainty about a given function (exploration) or maximizing the expected results (exploitation). This way, the algorithm can get from initially random parameters to better and better results as the learning progresses.
In order to perform effectively within a time constraint imposed on the search process, the AutoML module employs a Hyperband Bandit-based algorithm combined with Successive Halving. The algorithm, based on evaluated configurations, assigns a budget (as number of training epochs, declared by the user) to the given configuration in order to allow sufficient training. At later stages, better-performing configurations can receive an increased budget to further improve the model.
Based on the resulting configuration, the models can be trained and evaluated. For this purpose, we split the dataset into:
- a training set - used for training
- a validation set - used for evaluation and selecting the best models
- a test set - also used for evaluation, but results are only presented as additional information
In order not to redundantly train models that are too large, we implemented a model size check which rejects models larger than available space in board’s RAM.
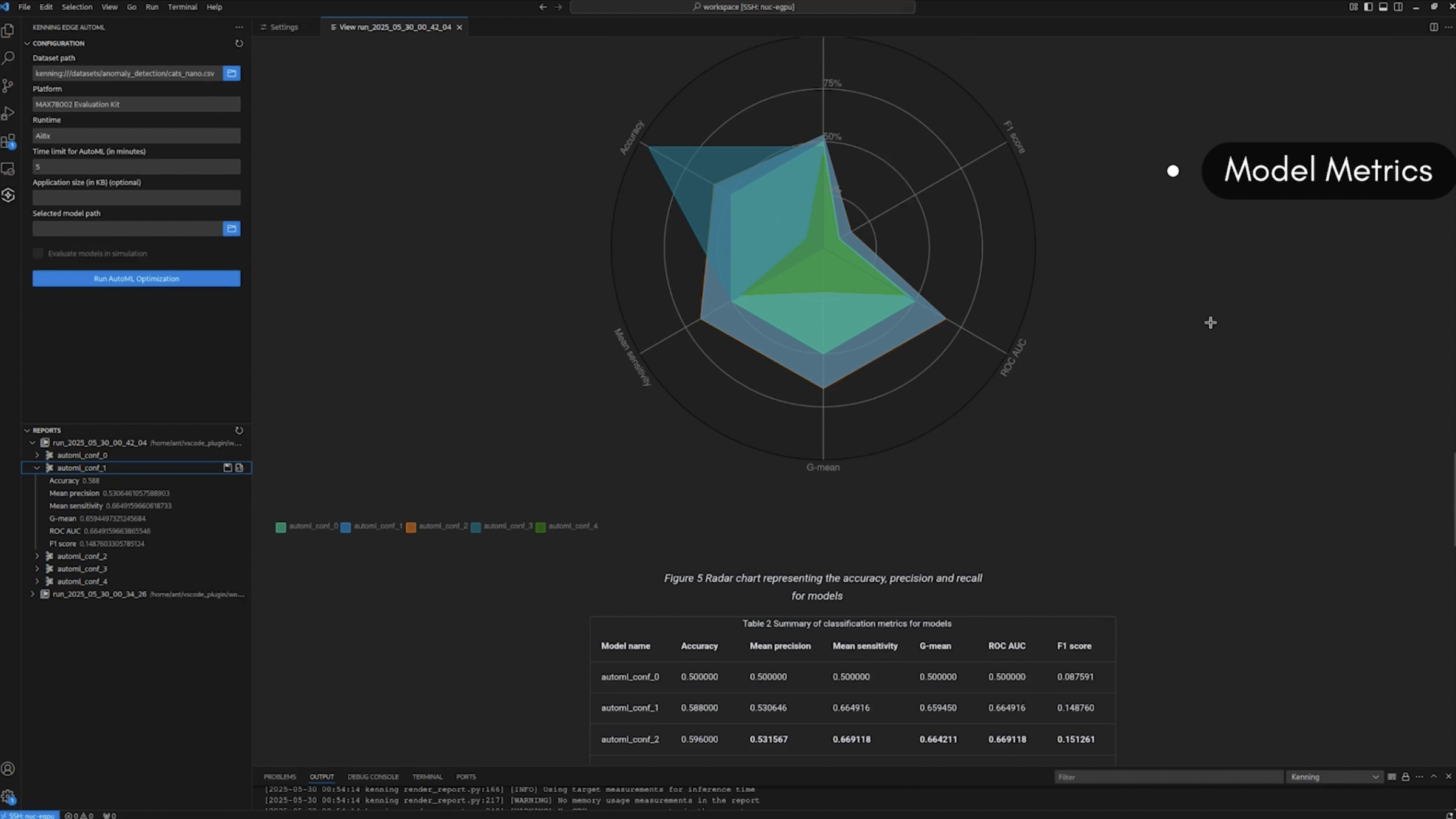
The models produced this way can then be passed to the standard Kenning flow for optimization, evaluation and comparison in the form of a report, all of which will be available in the upcoming VS Code plugin panel:
Simplified setup with platform configurations in Kenning
To further simplify the deployment of models on various platforms in Kenning, we introduced an initial (and extensible) database of available targets. So far, the user was required to provide information about the platform, including:
- the target CPU architecture
- the target accelerator
- in case of simulation: RESC and REPL definitions for Renode
- compilation flags (for optimizers)
- UART port (now found using a wildcard)
Our aim was to simplify this so that the user would only need to know the name of the platform, e.g. MAX32690 Evaluation Kit, or max32690fthr/max32690/m4 (Zephyr-like format).
We also introduced a new core class called Platform, which can parse multiple sources of platform definitions and contains all necessary data for:
- compilation (
compilation_flags) - flashing to HW (e.g.
openocd_flash_cmd) - simulation (
platform_resc_path) - communication (e.g.
baud_rate) - defining model constrains (
flash_size_kb,ram_size_kb) - automatically finding its UART port (
uart_port_wildcard) and specifying its baud rate - choosing the platform type (
default_platform)
The platform definition for the MAX32690 look as follows:
max32690evkit/max32690/m4:
display_name: MAX32690 Evaluation Kit
flash_size_kb: 3072
ram_size_kb: 128
uart_port_wildcard: /dev/serial/by-id/usb-FTDI_FT231X_USB_UART_*-if00-port0
uart_baudrate: 115200
uart_log_baudrate: 115200
compilation_flags:
- "-keys=arm_cpu,cpu"
- "-device=arm_cpu"
- "-march=armv7e-m"
- "-mcpu=cortex-m4"
- "-model=max32690"
openocd_flash_cmd:
- source [find interface/cmsis-dap.cfg]
- source [find target/max32690.cfg]
- init
- targets
- reset init
- flash write_image erase {binary_path}
- reset run
- shutdown
platform_resc_path: gh://antmicro:kenning-zephyr-runtime/renode/scripts/max32690evkit.resc;branch=main
default_platform: ZephyrPlatformBased on this description, Kenning will know that the MAX32690 Evaluation Kit has 3072KB of Flash, and 128KB of RAM on board. To further simplify connecting to the device, a platform description can also include a uart_port_wildcard, which provides a regular expression to find the symbolic link pointing to the UART device for communication with the board.
Such a platform configuration eliminates the need for manually providing various necessary parameters to Optimizer, Protocol or Runtime classes by simply including them as part of a scenario, as visible here:
# definition of the platform running Zephyr RTOS
platform:
type: ZephyrPlatform
parameters:
name: max32690evkit/max32690/m4
# to run inference on actual hardware, change simulated to false
simulated: true
zephyr_build_path: ./build/
# model wrapper for the VAE anomaly detection model
model_wrapper:
type: PyTorchAnomalyDetectionVAE
parameters:
model_path: ./vae_cats.pth
# A dataset used for evaluating the model
dataset:
type: AnomalyDetectionDataset
parameters:
dataset_root: ./workspace/dataset
csv_file: https://zenodo.org/records/8338435/files/data.csv
# run TVM compiler - target information will be extracted from Platform
optimizers:
- type: TVMCompiler
parameters:
compiled_model_path: ./workspace/vae_cats.graph_dataImprovements in Zephyr and Renode integration
To facilitate AutoML module integration with standalone Zephyr applications, Antmicro introduced several improvements to Kenning Zephyr Runtime, including two new CMake macros.
The first macro, kenning_add_board_repl_target, adds a board-repl target. After using this macro in a standalone app, it is possible to generate a .repl file for the target board that is used for simulation in Renode. The macro is defined in the board_repl.cmake file.
The other is kenning_gen_model_header which generates a C header with:
model_struct- model structure overview (number of inputs and outputs, their shapes and data types)QUANTIZATION_parameters - provide information on quantizing inputs and dequantizing outputsmodel_data- provides weights and other data for the model
This improvement eliminates the need for the user to manually compile the model and define its struct - now it is done automatically based on the provided model and its IO specification. The macro is defined in the gen_model_header.cmake.
The snippet below provides usage examples for both macros.
cmake_minimum_required(VERSION 3.13.1)
find_package(Zephyr REQUIRED HINTS $ENV{ZEPHYR_BASE})
project(demo_app LANGUAGES C)
# if model path starts with "./" make it absolute
if(CONFIG_KENNING_MODEL_PATH MATCHES "^./.*")
set(CONFIG_KENNING_MODEL_PATH "${CMAKE_CURRENT_SOURCE_DIR}/../${CONFIG_KENNING_MODEL_PATH}")
endif(CONFIG_KENNING_MODEL_PATH MATCHES "^./.*")
kenning_gen_model_header("${CMAKE_CURRENT_BINARY_DIR}/src/model_data.h")
kenning_add_board_repl_target()
include_directories("${CMAKE_CURRENT_SOURCE_DIR}/src" "${CMAKE_CURRENT_BINARY_DIR}/src")
target_sources(app PRIVATE src/main.c)The current implementation can also generate a TFLite OpResolver class for TFLiteOptimizer based on the provided model, so that only the operations that are required are included, eliminating the need for manual modifications in order to save memory. In Kenning Zephyr Runtime, the resolver is generated during runtime build and included in the binary.
For a minimal sample of an application using Kenning Zephyr Runtime, refer to the antmicro/kenning-zephyr-runtime-example-app repository.
Demo: finding the right model for an anomaly detection problem for the MAX32690 platform
Preparing the environment
Start by cloning the sample app and open it in VS Code.
git clone https://github.com/antmicro/kenning-zephyr-runtime-example-app.git sample-app
cd ./sample-appBuild a Docker container and run it using sample-app directory. The container contains all dependencies: Zephyr SDK, Renode and Kenning.
docker build -t kenning-automl environments/
docker run --rm -it --name automl -w $(pwd) -v $(pwd):$(pwd) kenning-automl:latest bashNow initialize the Zephyr app:
west init -l app
west update
west zephyr-exportThis should clone all Zephyr modules required to build Kenning Zephyr Runtime.
Now initialize Kenning Zephyr Runtime:
pushd ./kenning-zephyr-runtime
./scripts/prepare_zephyr_env.sh
./scripts/prepare_modules.sh
popdAutoML
Now you can use the AutoML pipeline in kenning-zephyr-runtime/kenning-scenarios/renode-zephyr-auto-tflite-automl-vae-max32690.yml. The AutoML definition looks as follows:
automl:
# Implementation of the AutoML flow using AutoPyTorch
type: AutoPyTorchML
parameters:
# Time limit for AutoML task (in minutes)
time_limit: 3
# List of model architectures used for AutoML,
# represented by ModelWrapper (has to implement AutoMLModel class)
use_models:
- PyTorchAnomalyDetectionVAE
# Directory storing AutoML results
output_directory: ./workspace/automl-results
# AutoPyTorch-specific options
# Chosen metric to optimize
optimize_metric: f1
# Size of the application that will use generated models
application_size: 75.5
...To run the AutoML flow, once the steps listed above are done, simply run:
kenning automl optimize test report
--cfg ./kenning-zephyr-runtime/kenning-scenarios/renode-zephyr-auto-tflite-automl-vae-max32690
.yml
--report-path ./workspace/automl-report/report.md
--allow-failures --to-html --verbosity INFO
--comparison-only --skip-general-informationThis command will:
- Run the AutoML flow and look for best-performing models for 3 minutes, excluding all models that won’t fit into the device based on its Flash, RAM and
application_size - Pick at most 5 best-performing models in terms of quality
- Evaluate the models on simulated hardware
- Generate a report and place it in the
workspace/automl-report/report/report.htmldirectory - Generate optimized models (
vae.<id>.tflite), their AutoML-derived configuration (automl_conf_<id>.yml) and IO specification files for Kenning (vae.<id>.tflite.json) in theworkspace/automl-results/directory.
The HTML report provides information needed for selecting a model that fits the user’s needs in terms of size, speed and quality.
Sample Zephyr App
Assuming that the model chosen from the AutoML flow is located in workspace/automl-results/vae.0.tflite, you can build the sample app using west by executing this command:
west build -p always -b max32690evkit/max32690/m4 app -- -DEXTRA_CONF_FILE="tflite.conf" -DCONFIG_KENNING_MODEL_PATH="$(pwd)/workspace/automl-results/vae.0.tflite"Now you can either run the app on the Renode-simulated board or on actual hardware.
To run it in Renode simulation, build the platform REPL file, which is used to create a Renode platform:
west build -t board-replThen execute:
./kenning-zephyr-runtime/scripts/run_renode.py --no-kcommsThe sample app loads the model, performs inference on random data and then logs performance metrics every ~2 seconds.
Example output:
Starting Renode simulation. Press CTRL+C to exit.
*** Booting Zephyr OS build v4.1.0-rc3-16-g5736aedd022e ***
I: 521 inference iterations done in 1811 ms (3.476 ms/it)
I: 529 inference iterations done in 1820 ms (3.440 ms/it)
I: 529 inference iterations done in 1804 ms (3.410 ms/it)
I: 526 inference iterations done in 1773 ms (3.371 ms/it)Simulation can be stopped with CTRL+C.
Accelerate AI model creation for embedded devices
The new AutoML module along with a plugin exposing its functionality in the VS Code IDE bring closer the common goal of Analog Devices and Antmicro for embedded engineers to reliably and quickly create AI models for devices based on the MAX32690 as well as other MCUs. The future of this joint Antmicro and Analog Devices project holds an upcoming release of the VS Code plugin discussed above, more baseline models dedicated to various AI task types, support for more target platforms as well as improvements in model evaluation and selection.
If you’re interested in developing AI-enabled embedded systems, and you would like to take advantage of the model creation, optimization, deployment and benchmarking capabilities that Kenning offers, as well as integrate the framework with your workflows and adapt to your target platforms, reach out at contact@antmicro.com to discuss your use case.