Tailoring neural network models to fit on resource-constrained devices is a multi-criterion optimization problem, difficult or impossible to solve manually. Antmicro has been working with Analog Devices, Inc (ADI) to add an AutoML flow to Kenning, our open source AI optimization and deployment framework, to automate the search for optimal models for specific tasks and hardware platforms.
After an initial release described in our previous blog note, and showcased at Embedded World earlier this year, we have been further expanding the AutoML features in Kenning, creating a unified pipeline for fully automated training and deployment of models generated with Neural Architecture Search (NAS) on memory-constrained devices. Updates include further improving the flow, enhancing the checks for devices’ constraints during model generation, and adding the tracking of AutoML search and training process which produces a comprehensive report in Kenning.
As part of our collaboration with Analog Devices, we also introduced support for ADI’s dedicated Convolutional Neural Network (CNN) Accelerator, found in MCUs such as the MAX78002, both in Kenning and Zephyr RTOS. We extended the AutoML flow and Platforms in Kenning to support optimizing and compiling models for various AI accelerators, and it’s now possible to easily define custom constraint checks to take accelerator-specific limitations into account, which this article will describe in more detail.

Deploying models on MAX78002’s CNN Accelerator
ADI’s MAX78002 platform features a CNN accelerator which allows loading and processing larger models (thanks to the dedicated CNN data memory), as well as efficiently processing convolutions with pooling and selected activation functions. It comes with an ai8x-synthesis tool that converts the models trained using the ai8x-training framework to bare-metal C code which enables the execution of the model on the accelerator.
As in many other neural network accelerators for embedded platforms, while providing a significant speedup compared to executing on an (unaccelerated) MCU, this comes with numerous requirements regarding the model architecture and used layers, such as:
- Weights, bias values and data need to be quantized (a common limitation across various accelerators)
- Supported operations are 1D and 2D convolution layers, 2D transposed convolution layers, basic element-wise operations, pooling (fused with convolutions), basic activation functions (ReLU, clamped linear, absolute value)
- Kernel sizes in 2D convolutions must be 1x1 or 3x3
- Padding in 2D convolutions can be 0, 1 or 2
- Maximum size of weights and inputs relies on other layers and device constraints
To make the process of creating models for such accelerators less tedious by automatically conforming to their constraints, Antmicro worked with ADI’s MAX78002 as a CNN-accelerated reference platform, and introduced relevant changes to Kenning that ultimately allow generating compliant models with AutoML.
Our work consisted of two fundamental efforts: adjusting the AutoML flow in Kenning to account for custom constraints, and adding the support for the AI8X toolchain and inference engine in both Kenning and Kenning Zephyr Runtime.
Preparing an AutoML search in Kenning for AI accelerators
Since releasing the developments described in Antmicro’s previous blog note, we significantly improved the compatibility checks of models generated by NAS before their training in order to support the processing of both microcontrollers and accelerators. Previously, the checks focused only on comparing platform memory constraints to model size, approximated from the number of parameters, before applying any optimizations.
The previous heuristic led to rejecting models with a larger number of parameters, whereas, after optimization, those same models usually end up being significantly smaller. The current approach takes the model generated by NAS, applies the requested optimizations, such as quantization or pruning (minimizing the time spent on calibration or fine-tuning to several dataset samples, since the models are not trained yet at that point), compiles the model, and checks its final size. With this method, we get an exact target model size, further stabilizing the AutoML model search, which allows us to train larger models, saturating the available resource usage by the model, and thus leading to even better solutions in terms of model quality.
The second adjustment to the compatibility checks was done with AI accelerators (such as the aforementioned ADI CNN Accelerator) and target inference libraries in mind. Currently, in Optimizer’s compile method for optimizing and compiling models, it is possible to raise exceptions and errors whenever the input model is not compatible with the target platform or inference library. Checks can be implemented manually or with the help of the compiler’s libraries. This unifies and significantly simplifies the process of searching for models for AI accelerators, since we can easily verify the model’s compatibility using either vendor-provided tools, our own custom checks, or the target platform itself.
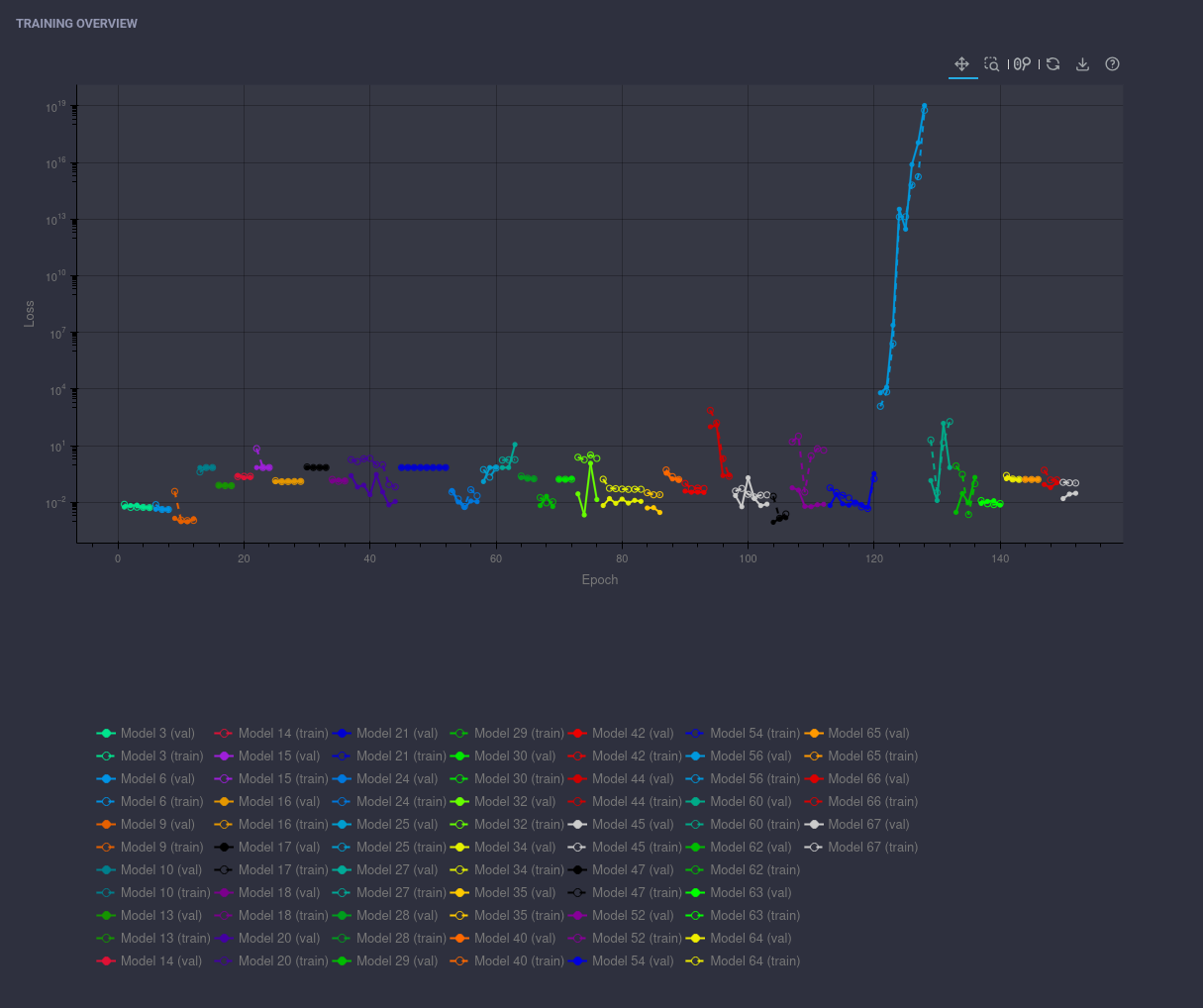
On top of the adjustments specific to memory and accelerator constraints described above, we extended the collection of training-specific metrics and logs in the AutoML process to allow for an in-depth analysis of the entire model generation, training and selection process. The collected data can later be visualized in Kenning’s reports: on top of displaying the quality, performance and utilization details of the selected (best) models from the AutoML process, you also get plots of loss functions for all generated AutoML models over time, allowing to examine stability and lengths (budgets) of the training processes, quality changes over time and the number of successful-versus-failed generations/trainings.
This is especially useful for advanced developers and data scientists, as it gives them a better understanding of whether the given configuration space is well-defined for the given platform and dataset.
(For an interactive version of the diagram, visit the desktop version of the website)
Adding support for the MAX78002 CNN Accelerator in Kenning
Support for the MAX78002 CNN Accelerator required adding the AI8XCompiler in Kenning to prepare the model implementation. The overall flow of the AI8X model compilation is visualized below.

The AI8XCompiler takes the trained (or generated) model and optionally adjusts its structure by fusing certain layers to blocks supported by the AI8X flow. Next, the compiler generates a YAML file with the configuration of the CNN Accelerator based on the model’s structure, which is later used to generate C sources with the bare-metal implementation of the model for the CNN Accelerator. Finally, AI8XCompiler takes the generated sources, converting them and adjusting for use in Zephyr RTOS, and creating a cnn_model.c file with the model implementation, and a cnn_model.bin file with the model data.
With regard to the model’s compatibility with AutoML, we run some initial checks verifying if the model is compliant with the AI8X flow (i.e. contains supported layers and data formats), make adjustments if necessary (or raise errors if that’s not possible), and run the ai8x-synthesis tool to check whether it raises any errors when compiling the model for the CNN accelerator.
In Kenning Zephyr Runtime, we introduced an AI8X inference engine backend that takes the model implementation and allows the user to prepare that model and run inference. First, we implemented methods for configuring the CNN Accelerator (setting up the clock, enabling the accelerator and configuring interrupts). We also implemented methods for loading weights and inputs using Kenning Zephyr Runtime’s data loaders; this enables sending data directly from Kenning’s host to the accelerator without the need to load an entire model in the MCU’s memory, which would not be able to hold larger models supported by the accelerator. We also added methods to Kenning Zephyr Runtime providing a unified API similar to other inference libraries (microTVM, LiteRT, IREE) which use the model implementation generated by ai8x-synthesis and Kenning’s codegen.
In the end, as usual, the optimization, deployment and testing of models boils down to a simple Kenning call that connects to the target device for evaluation purposes:
With all of the above in place, you can easily deploy AutoML-generated models on MAX78002’s CNN Accelerator, which for a simple anomaly detection model allows for inference time 367x (!) faster compared to the best inference time for the same model without the accelerator.

Expanding the open source AI ecosystem
To enable running efficient AI models on the MAX78002 CNN Accelerator in Zephyr RTOS, Antmicro also made adequate adjustments to several related open source projects for a smooth, end-to-end workflow.
Zephyr itself only required a small clock configuration update to make it possible to enable clock in the AI Accelerator.
On the AutoML side, we introduced support in our fork of AutoPyTorch to enable passing pre-training checks from Kenning, as well as adjusted the library for Mac OS running on ARM platforms. With this, we also introduced initial support for Mac OS platforms in Kenning.
We also made some adjustments in the AI8X tooling (in ai8x-training and distiller) to improve the CNN Accelerator configuration for custom models generated by AutoML.
With the constantly growing number of supported platforms (currently topping 1000) supported by the Zephyr RTOS, and, by extension, the AutoML flow in Kenning described here, simplifying automated model generation for embedded AI accelerators automatically lays the groundwork for a breadth of embedded hardware. What is more, on most of those platforms (more than 600, as of the time of writing), you can also use Antmicro’s open source Renode simulation framework to deploy and test the models without having to procure the relevant hardware. As a vendor or developer, you can also conveniently track - or work with us to demonstrate - Zephyr/Renode/Kenning/AutoML support in the Renode Zephyr Dashboard.
AutoML for your next-gen embedded device
The AutoML Kenning module was built and released in collaboration with Analog Devices to help embedded engineers quickly select, optimize and deploy AI models. The described methodology, featuring a complete open source toolchain based on Kenning paves the way for easy inclusion of new AI accelerators for the wide range of platforms supporting Linux and Zephyr. Developers can now easily access a mature development workflow involving AutoML, optimization and deployment pipelines supporting various inference libraries, and reproducible simulations for local development and CI testing. This further lowers the entry barriers for efficient AI development for embedded and brings together a number of open source technologies to support the growing landscape of platforms and accelerators in a concise manner.
If you are developing AI-enabled embedded systems, and the upgrades we described spark your interest, you can use AutoML in Kenning for model creation, optimization, deployment, and benchmarking. Reach out to us at contact@antmicro.com to discuss your use case.