Antmicro’s Kenning framework, introduced during our work on the VEDLIoT edge AI research project, is being used in various local AI processing projects to create deployment flows and runtimes for Deep Neural Network applications on a variety of target hardware.
One of our last blog notes on Kenning covered introducing JSON-based pipelines and chains of optimizers to apply multiple optimizations to the model. There, we described how to create an optimization pipeline while demonstrating how a sample classification model can be iteratively optimized for x86 CPU execution. Since then, Antmicro has been continuously developing Kenning to extend its benchmarking and runtime capabilities, and this blog note will expand on the previously described example to show how the new features can be used in practice.

Comparing optimized models with Kenning
The render_report tool now has the ability to take multiple measurement files as input and create comparison reports in the form of text reports as well as comparison visualizations showing how the models differ from each other. When working on single model optimization, it is extremely useful to visually trace improvements (or regressions) of the model resource usage, inference speed and prediction quality.
Let’s consider the optimization steps for a MobileNetV2 model optimization on an x86 CPU discussed in the above mentioned blog note.
In all 5 output files with measurements, the command for rendering both per-model reports and a comparison report looks as follows:
python -m kenning.scenarios.render_report
"x86-optimization-comparison"
report/summary.rst
--measurements
build/native-out.json
build/tflite-fp32-out.json
build/tflite-int8-out.json
build/tvm-int8-out.json
build/tvm-avx2-int8-out.json
--root-dir report
--report-types performance classification
--img-dir report/imgs
--model-names
native tflite-fp32 tflite-int8 tvm-int8 tvm-avx2-int8In this command:
x86-optimization-comparisonis the title of the report,report/summary.rstis the file with the output report,- files provided in the
--measurementslist are the measurements collected using thekenning.scenarios.json_inference_testerscenario, --root-diris the directory where the report will be generated,--report-typesis a list of report types that should be included in the final report (performance metrics and classification quality),--img-diris the path to the directory where plots will be saved,--model-namesis the list of names for each measurement listed in--measurements- it is a readable representation used in the legends for the plots.
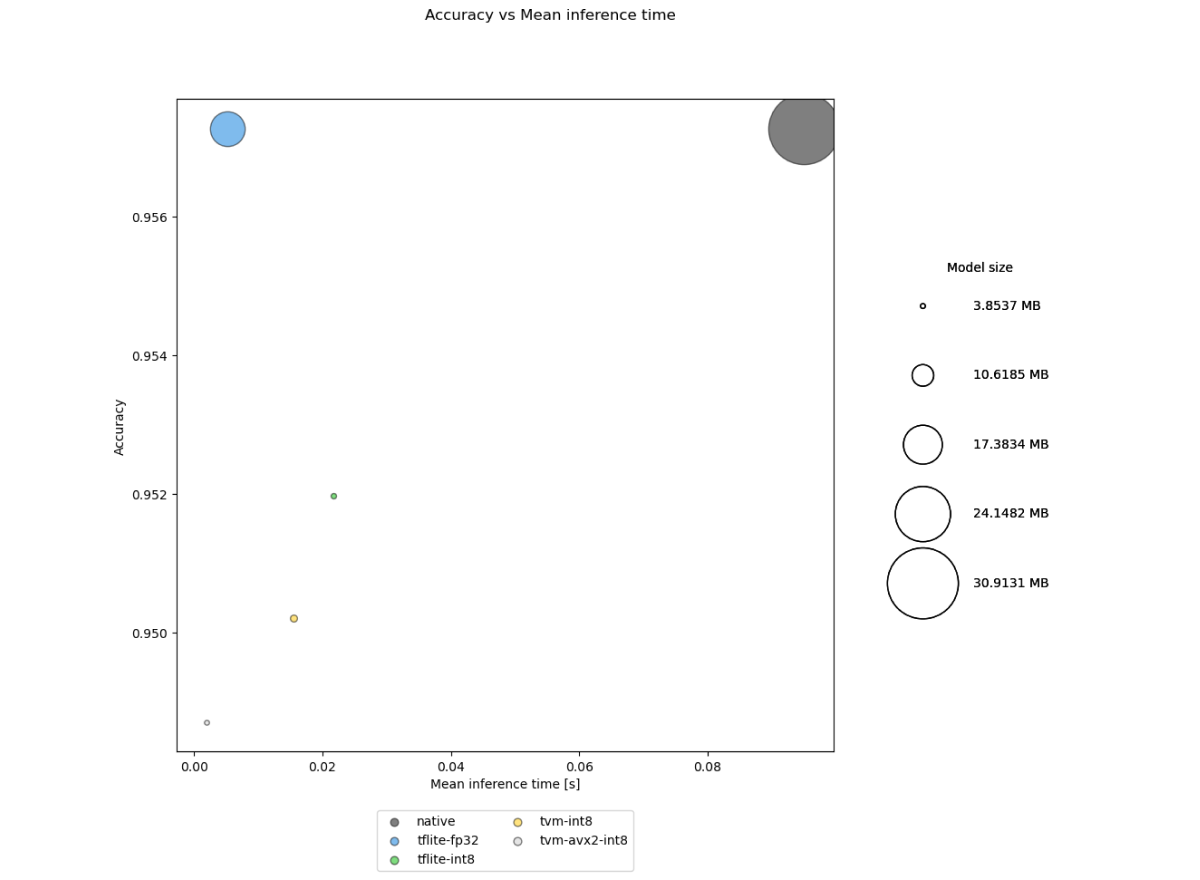
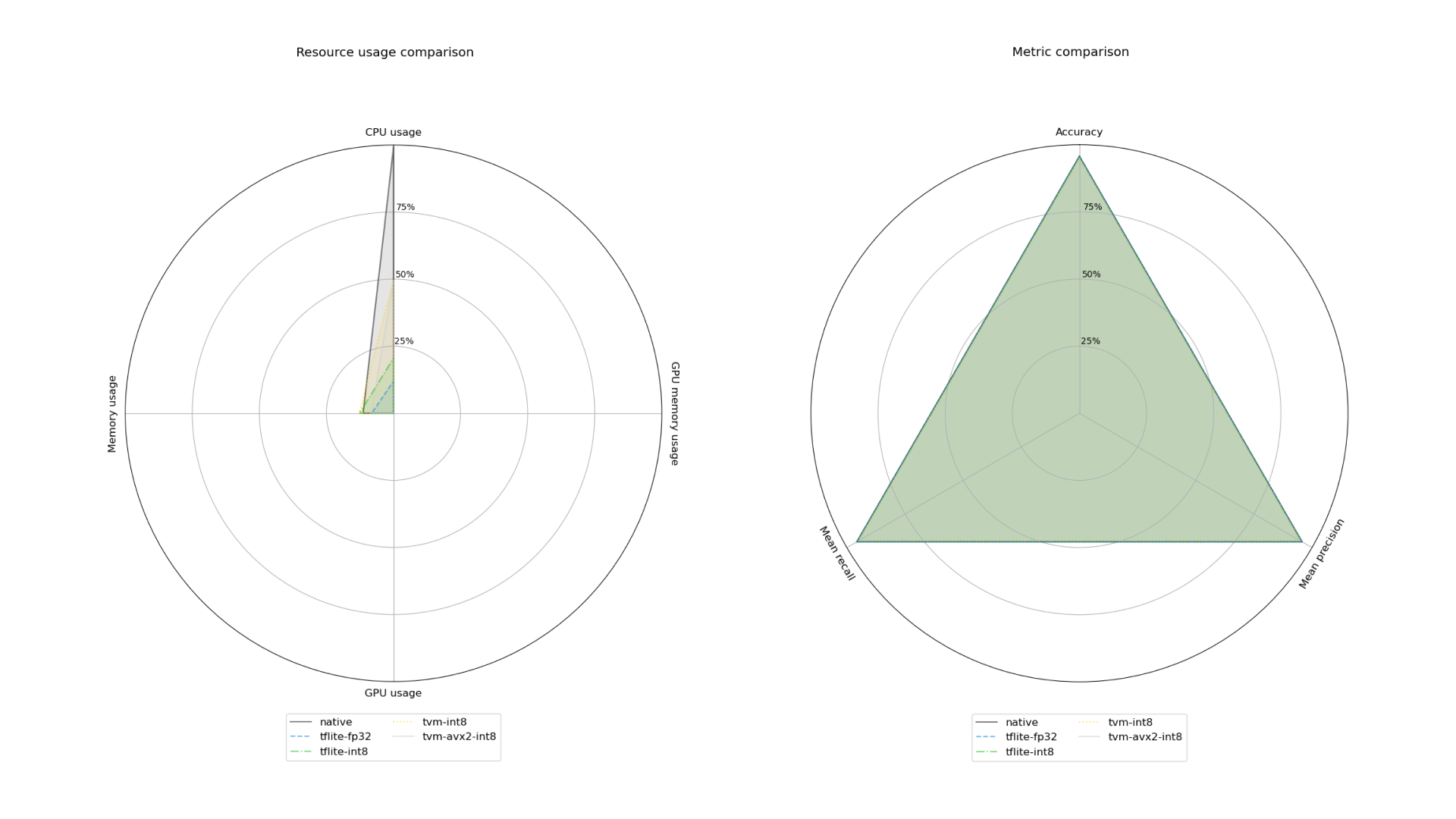
We can then receive comparison information in the following forms:
- Bubble plots representing accuracies, sizes and inference times for the models,
- Radar charts representing usage of resources and model quality metrics,
- Violin plots representing resource usage distribution,
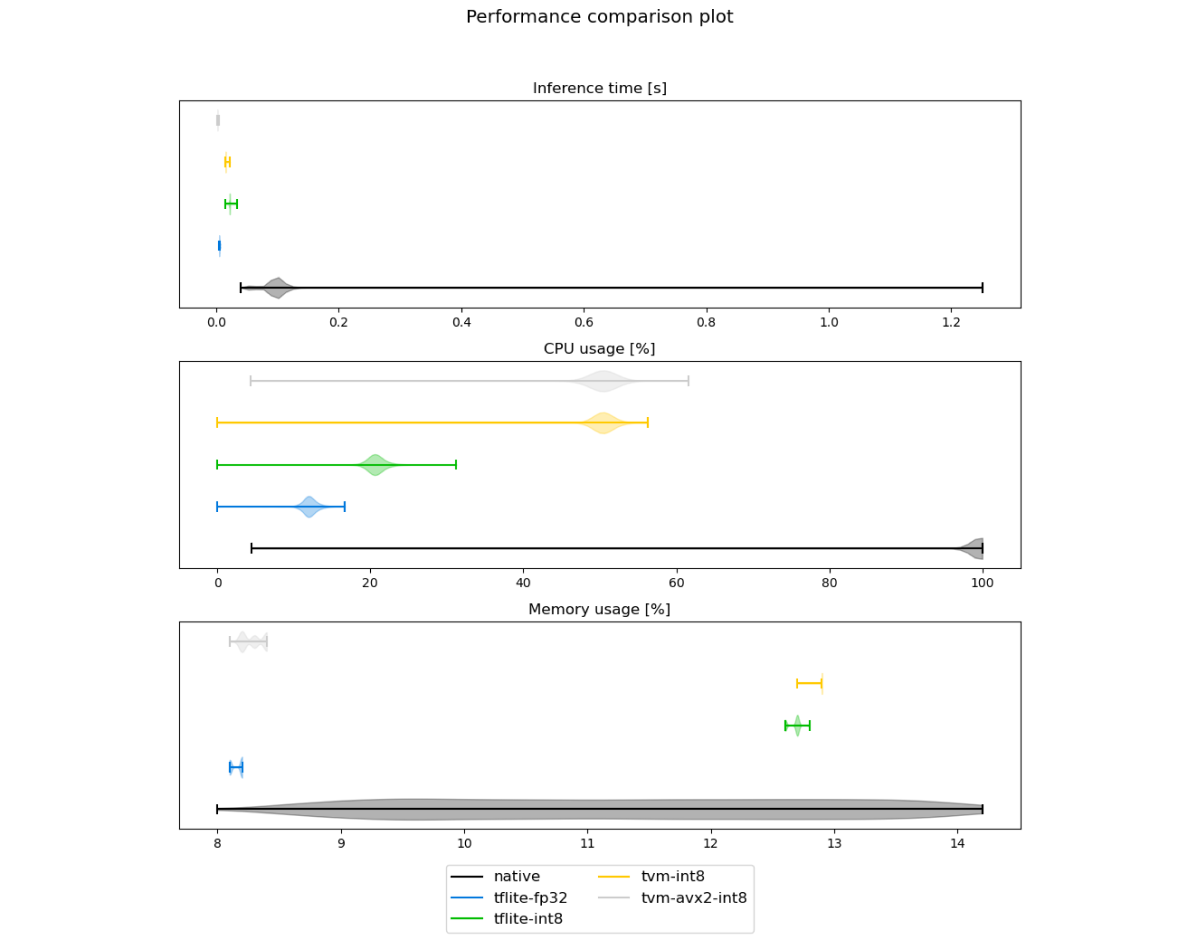
With the measurement collection and report rendering shown above, the process of tracking a model’s performance and quality improvements is much easier to follow, reproduce and analyze.
Model metadata
The next important improvement in Kenning was the addition of model metadata. Depending on the runtime and compilation framework, information about input names, shapes and element types may or may not be included. Also, the input and output names may be changed for some compilers, and the order of inputs and outputs may be changed for others.
Such changes in representation of inputs and outputs, especially when multiple optimizers are involved, can make it hard to determine, e.g. which of the current inputs corresponds to the original input.
What is more, while some compilers may add and store additional information about particular input, such as quantization parameters of the input tensor, the following compilers may drop this information.
To address this, we created input and output metadata handling, where all the information regarding inputs and outputs in the model is stored in the JSON model and updated by every Optimizer object, if necessary.
For example, model metadata for a native TensorFlow classification model may look as follows:
{
"input": [
{
"name": "input_1",
"shape": [1, 224, 224, 3],
"dtype": "float32"
}
],
"output": [
{
"name": "Predictions",
"shape": [1, 1000],
"dtype": "float32"
}
]
}After quantization with TFLite, the names of inputs and outputs, as well as the type, are changed.
In addition to this, quantization data for inputs and outputs (scales and zero points for quantization and dequantization purposes) is included:
{
"input": [
{
"name": "serving_default_input_1:0",
"shape": [1, 224, 224, 3],
"dtype": "int8",
"order": 0,
"scale": 0.007843137718737125,
"zero_point": -1,
"prequantized_dtype": "float32"
}
],
"output": [
{
"name": "StatefulPartitionedCall:0",
"shape": [1, 1000],
"dtype": "int8",
"order": 0,
"scale": 0.00390625,
"zero_point": -128,
"prequantized_dtype": "float32"
}
]
}The original order of inputs and outputs is stored in the order field. This metadata is used in ModelWrappers, Optimizers and Runtimes as a unified source of truth when it comes to information regarding inputs, outputs and other aspects of the model. In the nearest future, Antmicro will be adding more information, such as model classes and hyperparameters used in models, to Kenning.
Other improvements, revised documentation and more
On top of the two major features described above, the framework has also seen the following improvements:
- added YOLOv3 and YOLOv4 ModelWrappers with an improved collection of bounding boxes,
- added wrappers for COCO and ImageNet datasets,
- improved computing metrics for object detection models,
- added support for TensorRT library utilization in TVM Optimizer,
- overhauled the entire project documentation.
The new developments, combined with support for multiple optimization and compilation frameworks, make Kenning a comprehensive tool for benchmarking and testing DNN models on various hardware targets. While working on a wide range of edge AI projects, both for customer projects and internal R&D, Antmicro continues to improve the AI framework to fit a wide range of use cases. If you would like to benefit from these enhancements or are simply interested in learning how Kenning can be used in your AI pipeline, make sure to reach out to us at contact@antmicro.com.