The demand for deploying machine learning models, especially state-of-the-art deep neural networks on edge devices is rapidly growing. Edge AI allows to run inference locally, without the need for a connection to the cloud, which makes the technologies more portable and self-sufficient. Without the need for sending the data to the cloud, edge AI solutions are also much safer in terms of data privacy.
Deep neural networks are highly demanding algorithms that consist of a huge amount of linear algebra operations which are both compute- and memory-intensive. Running them directly on edge devices is either impossible due to lack of resources or impractical due to incredibly long processing time. Hence, it is crucial to optimize the models for a given target platform before deployment, using a deep learning compiler.
The ecosystem of machine learning frameworks and deep learning accelerators is evolving quickly, bringing an abundance of frameworks for model training, model optimization and compilation. They all differ in supported deep learning operators, models and features. In addition, deep learning compilers will each have their own list of supported edge devices, optimization techniques and model representations. Practice shows, on every level of deployment you will encounter significant diversity which means that making changes in your edge AI setup can be an unexpectedly tedious task, requiring lots of hand-tweaking.
Antmicro builds hardware and especially AI software for a variety of edge AI platforms such as NVIDIA Jetson, Coral, Movidius, various FPGA and various RISC-V platforms. To be able to use the right device for the right use case to maximize the results for our customers, we need our AI solutions to be portable across a variety of hardware, ML frameworks and cloud solutions. That is why we are introducing the Kenning framework, which provides an API for a uniform edge AI deployment flow regardless of the selected training framework and compiler.
Edge AI deployment stack
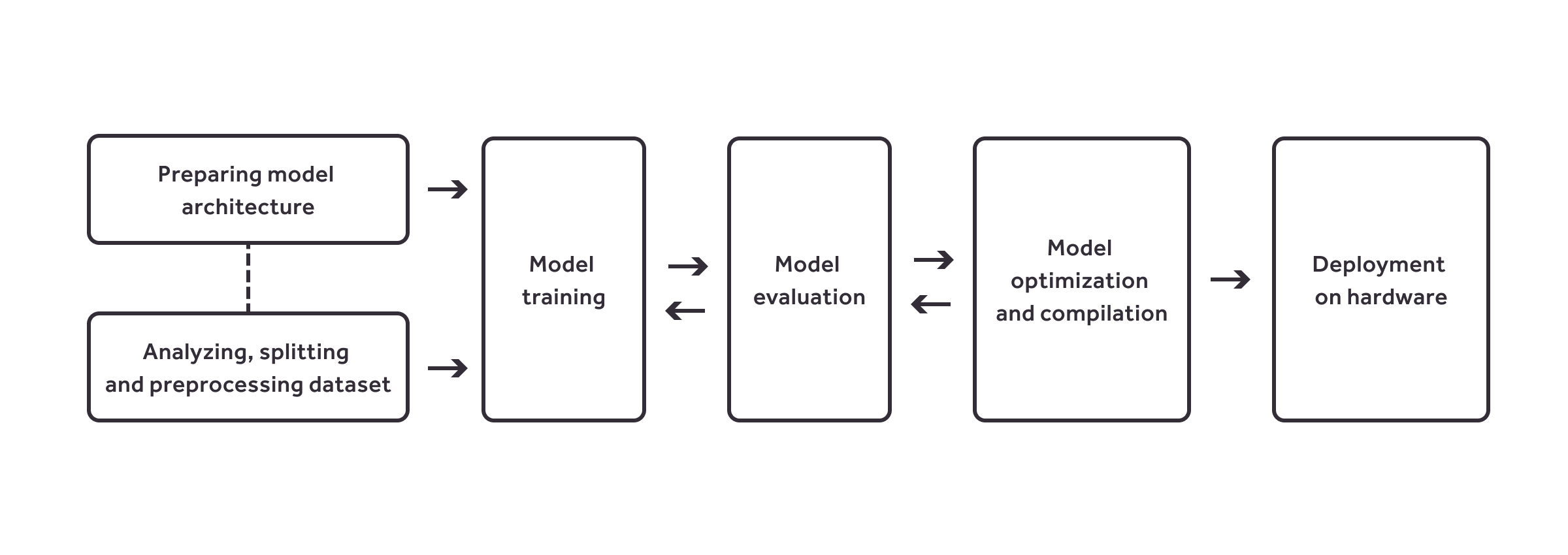
When creating Edge AI deployment stacks for our customers, on a high level we typically have to go through the following steps: 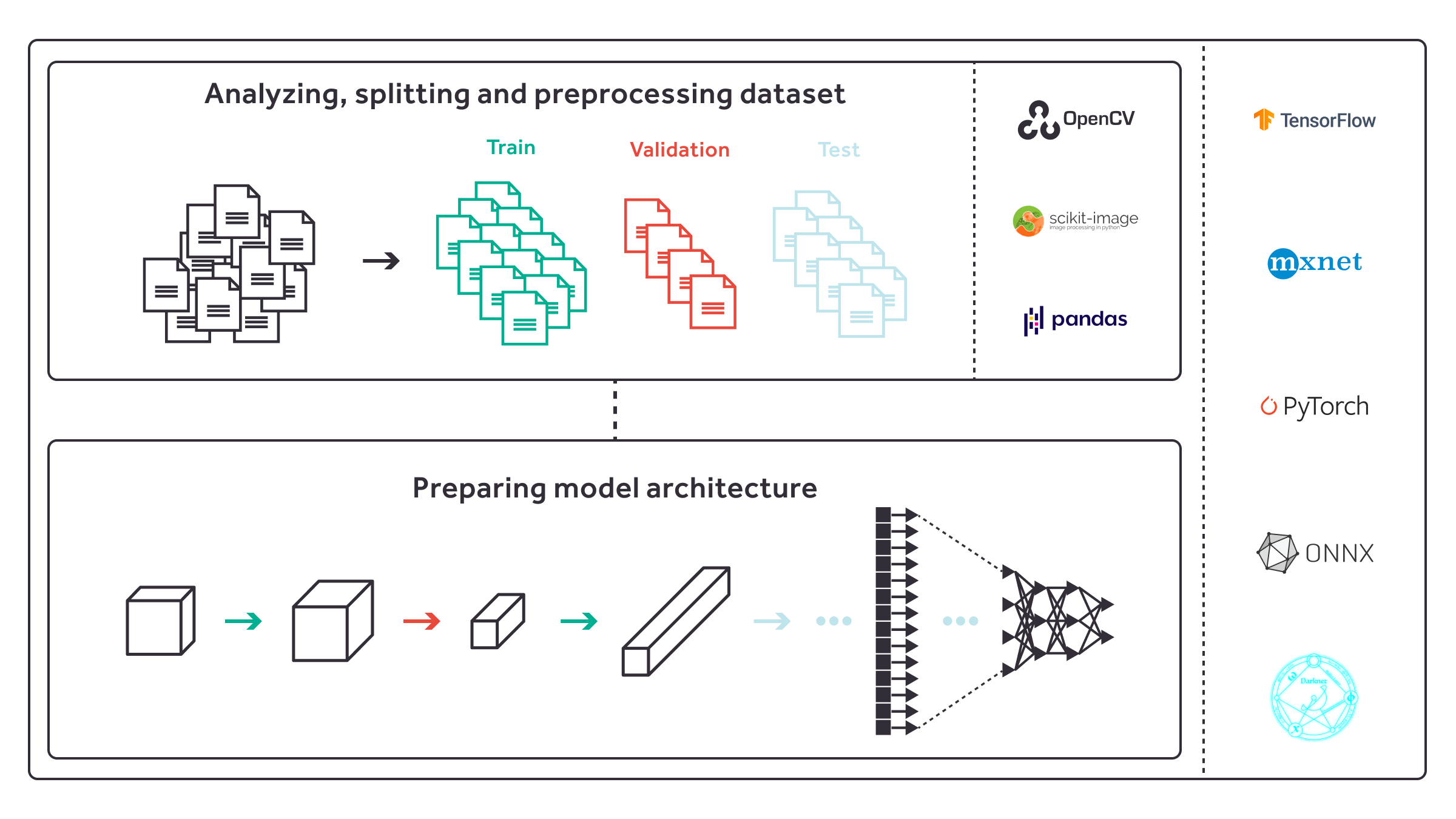
- Specify the task for the deep learning application
- Create a dataset for your task, or perhaps aggregate data found in existing datasets e.g. Kaggle, Google Dataset Search, Dataset List. Many datasets that can be found online are not suitable for commercial use, and often we help our clients in building/picking the right dataset for their application. We also create tools to assist in the process.
- Analyze the dataset, experiment and implement pre- and postprocessing routines, subdivite it into training, validation and test datasets.
- Select a deep learning model from existing state-of-the-art models, or design it from scratch.
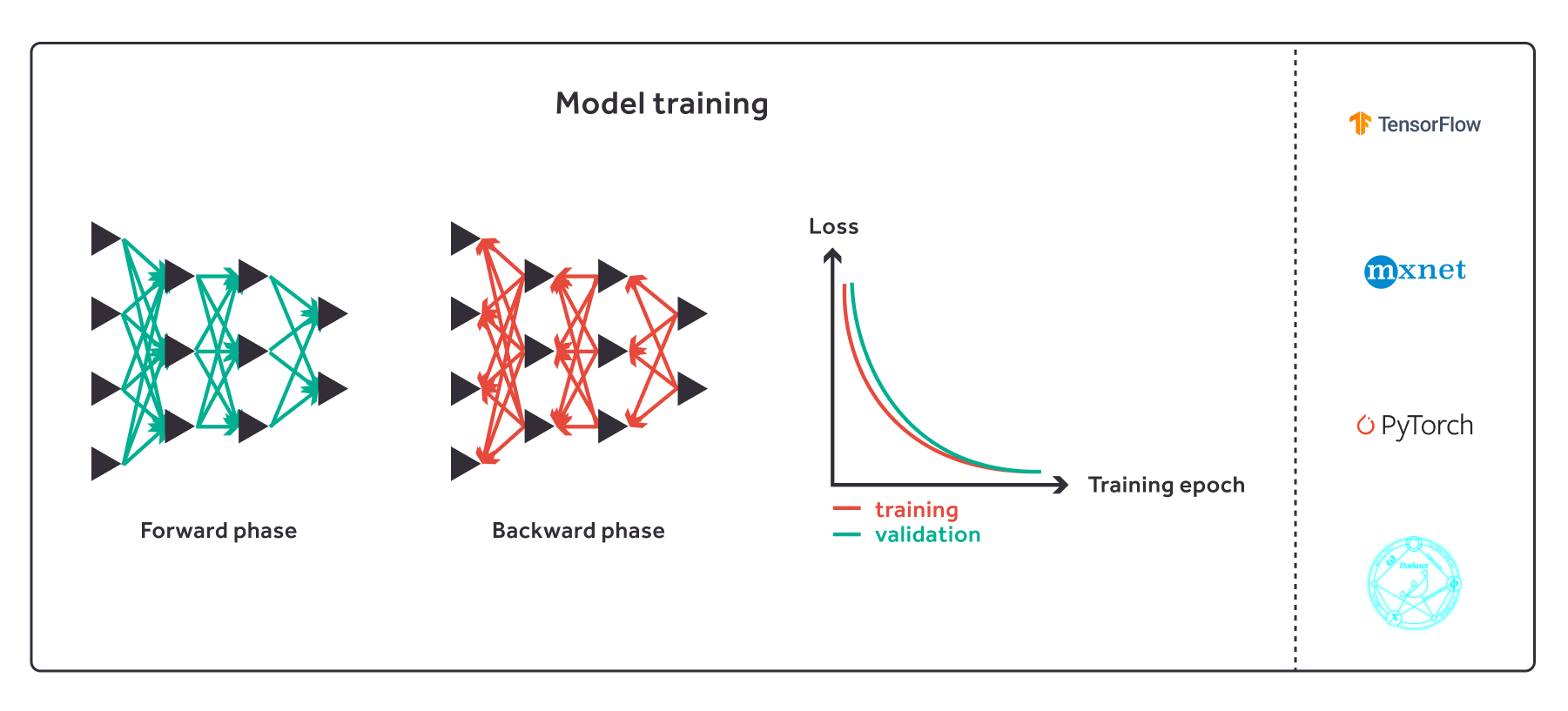
- Train the model using the prepared loss function and learning procedure.
- Evaluate and improve your model if necessary.
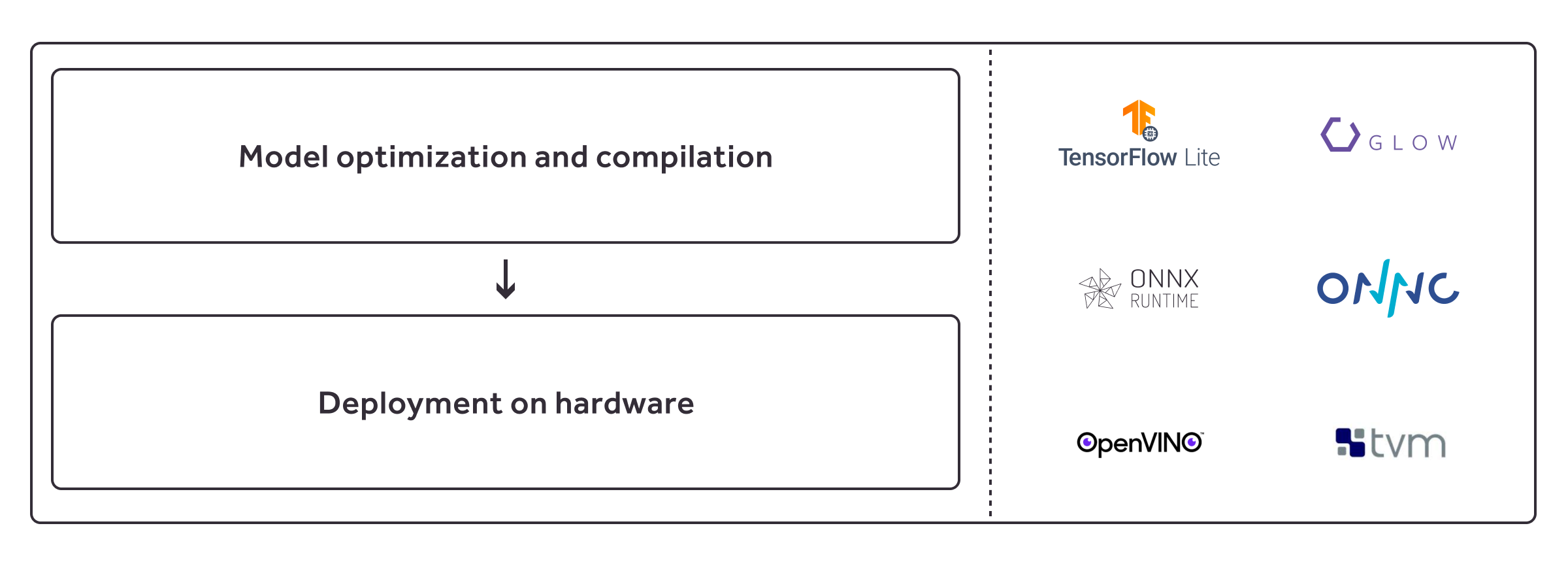
- Optimize the model using techniques such as pruning, quantization and clustering.
- Optimize the model using hardware-specific optimizations, and later compile it for the target hardware.
- Simulate or execute the model on the target hardware and evaluate the results in order to detect any quality loss, and improve it if necessary.
- Deploy the model on the target hardware (this in itself is a complex task; we help build edge AI pipeline deployment and update frameworks for in-field operation of devices ranging from agriculture and medicine to logistics, manufacturing, and more)
This flow applies regardless of the selected deep learning frameworks, optimizers or compilers, which however vary in supported deep learning models, optimizations and hardware platforms. This is particularly noticeable in hardware support in deep learning compilers. Switching between hardware platforms will often force us to change either parts of or the entire deployment flow, which makes apples-to-apples comparisons difficult and time-consuming. That’s where Kenning comes in.
The Kenning framework
![]()
Kenning is a new ML framework developed by Antmicro for testing and deploying deep learning applications on the edge. “Kenning” is an Old Norse term for a poetic, sometimes unexpected synonym, which gives away what our goal is with this framework - we want to make different AI platforms more equivalent, make AI pipelines easier to port between various edge platforms and offer a unified developing methodology for the vastness of emerging models, datasets, tools and techniques. And ultimately, to accelerate and support the opening up of crucial AI technology.
Kenning’s origin lies in a benchmarking framework implemented during our work on Very Efficient Deep Learning in IoT project. VEDLIoT is focused on building platform-independent AI for edge applications and exploring RISC-V (mentioned earlier in our blog in Very Efficient Deep Learning in IoT project with RISC-V and Renode.) That’s another instance of our constant efforts on many fronts towards more open AI solutions in general, aligning with our work around open source FPGA tooling, TF Lite Micro, Renode, CFU extensions for RISC-V and with other global leaders at CHIPS Alliance.
The aim of the project was to seamlessly run models from various frameworks (such as TensorFlow, PyTorch, MXNet, darknet) on various targets (NVIDIA Jetson devices, Intel Movidius, Google Coral etc.) using various compilers (Apache TVM, TensorFlow Lite, OpenVINO, Glow), provide an unified way of verifying the performance and model quality and automatically render the report for a given flow.
As it turned out during the development, Kenning’s applicability extends beyond benchmarking, and over time we developed it into a uniform framework for executing deep learning applications on various hardware platforms.
Kenning’s structure
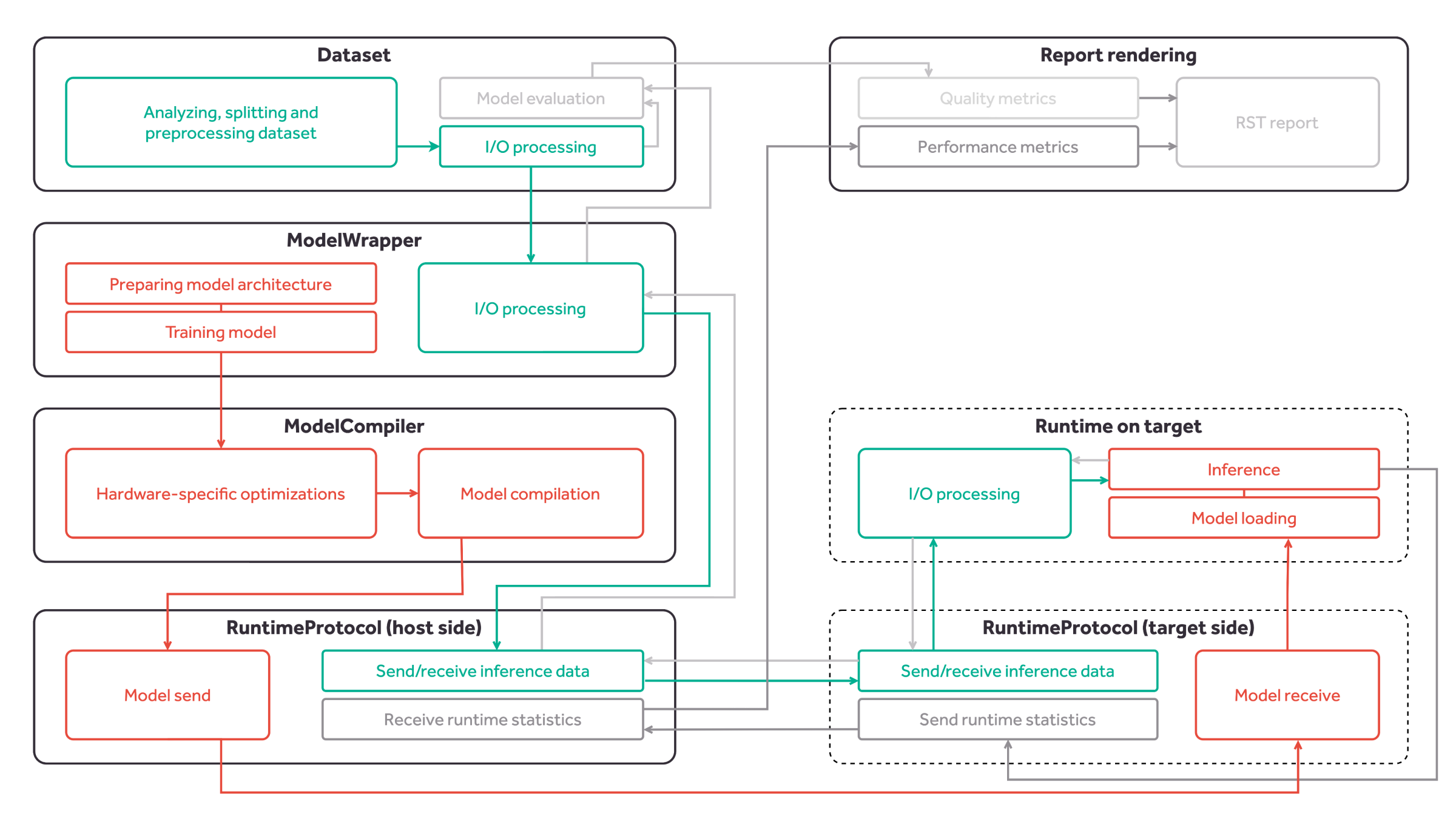
Technically, Kenning is a Python framework consisting of a set of useful classes:
- Dataset class - performs dataset downloading, preparation, input preprocessing, output postprocessing and model evaluation,
- Model wrapper class - trains the model, prepares the model, performs model-specific input preprocessing and output postprocessing, runs inference on host using native framework,
- Model compiler class - optimizes and compiles the model,
- Runtime class - loads the model, performs inference on compiled model, runs target-specific processing of inputs and outputs, and runs performance benchmarks
- Runtime Protocol class - implements the communication protocol between the host and the target.
In the end, the report renderer takes the runtime statistics and evaluation data to create a final report.
The classes listed above implement all of the deep learning deployment steps mentioned in the edge AI deployment stack.
The backend methods communicate with underlying learning and compiling frameworks, and the frontend methods are meant to provide a seamless communication between compatible dataset, learning, compilation and runtime objects.
The classes handle model compilation flows (model preparation and training, hardware-specific optimizations, model compilation, model passing to hardware, model loading and inference), testing flows (taking outputs from inference, measuring performance metrics during inference, evaluating the predictions in comparison with ground truth, rendering the report) and inference flows (receiving data, performing general data processing, performing model-specific I/O processing, performing hardware-specific I/O processing, running inference and sending back results). Each flow can work independently.
Tracking performance of DL applications on target hardware
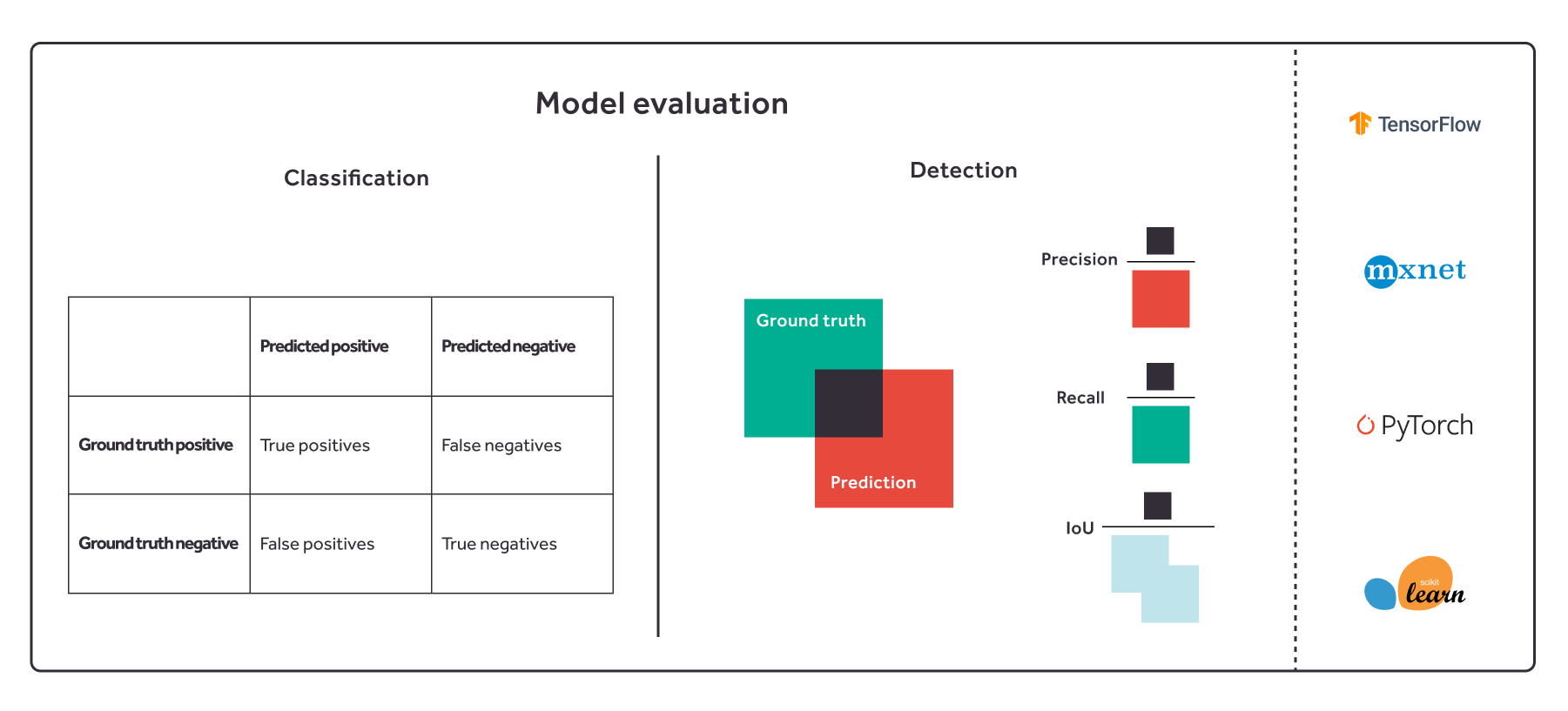
One of the advantages of Kenning is the possibility to easily verify the work of the model on your target hardware - it calculates both performance measures (like CPU usage, GPU usage, RAM and VRAM usages, inference time), and quality measures (accuracy, precision, recall, G-Mean for classification scenarios, and IoU, mAP for detection scenarios).
This allows the user to compare the same model against various target platforms, and also helps to track any quality regression during the optimization and compilation processes.
Kenning conveniently provides plots for performance measurements: 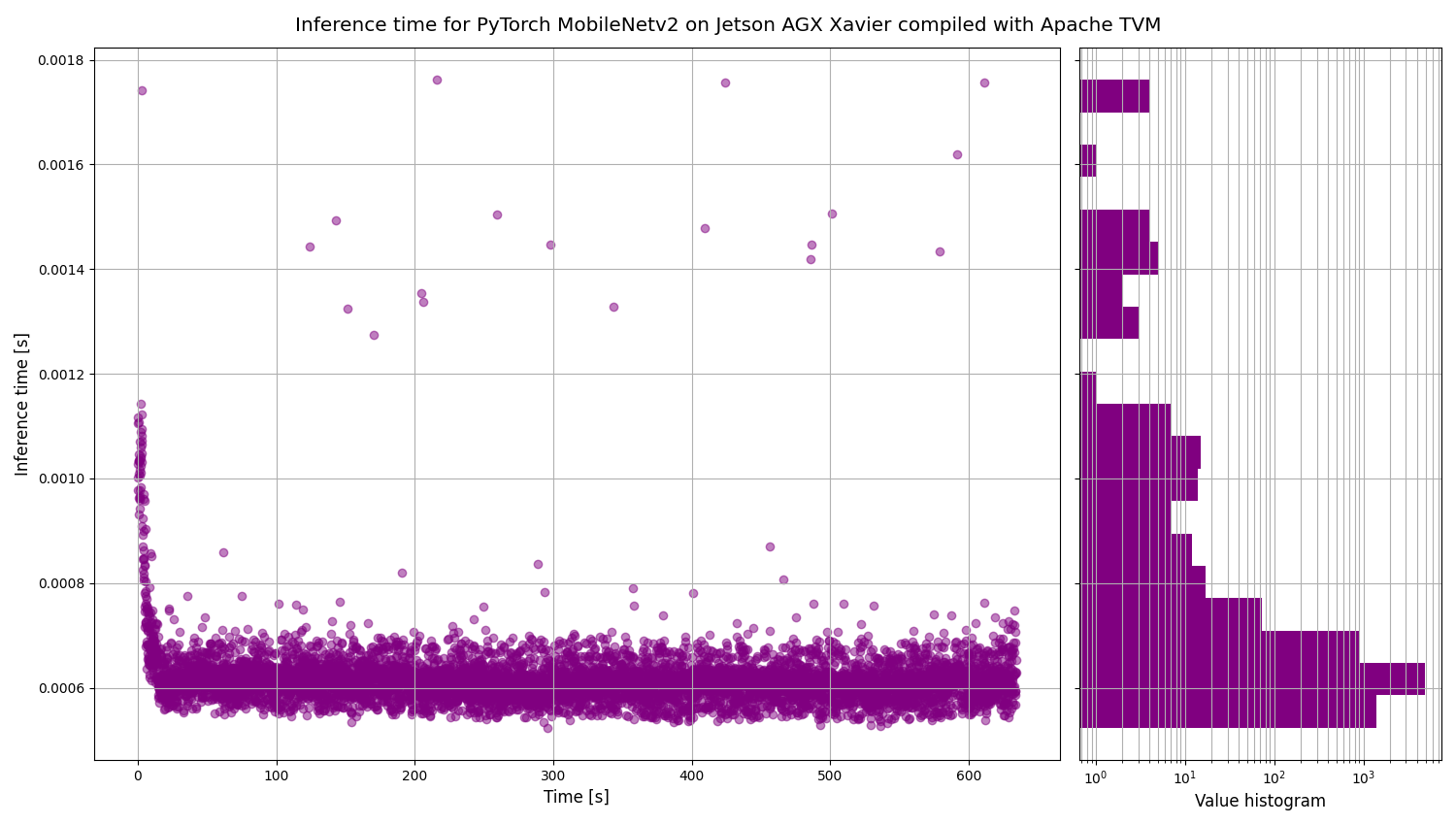 For the classification models, Kenning will compute a confusion matrix and other quality metrics, both per-class and global:
For the classification models, Kenning will compute a confusion matrix and other quality metrics, both per-class and global: 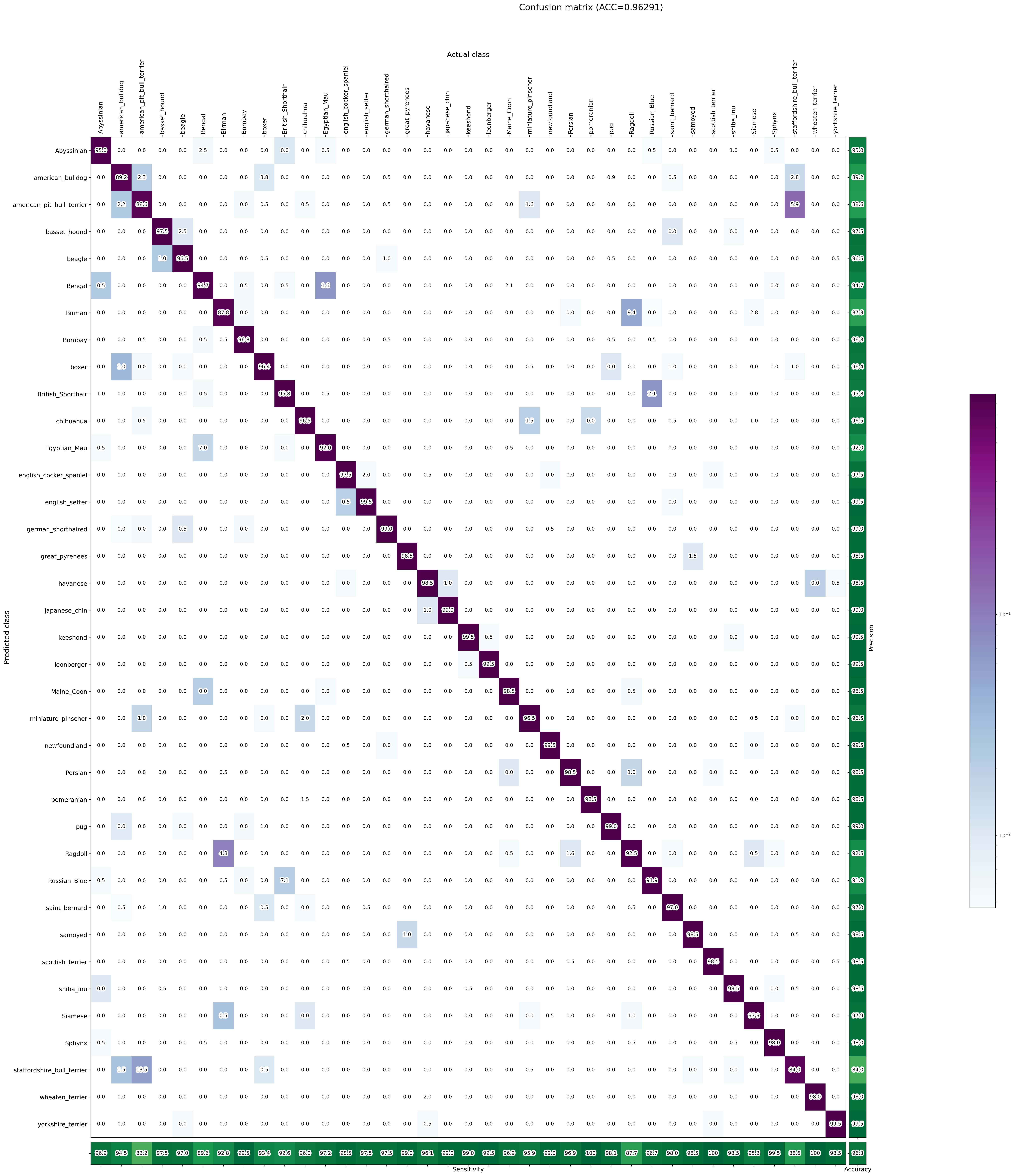
- Accuracy: 0.96271
- Top-5 accuracy: 0.99795
- Mean precision: 0.96272
- Mean sensitivity: 0.96291
- G-mean: 0.96215
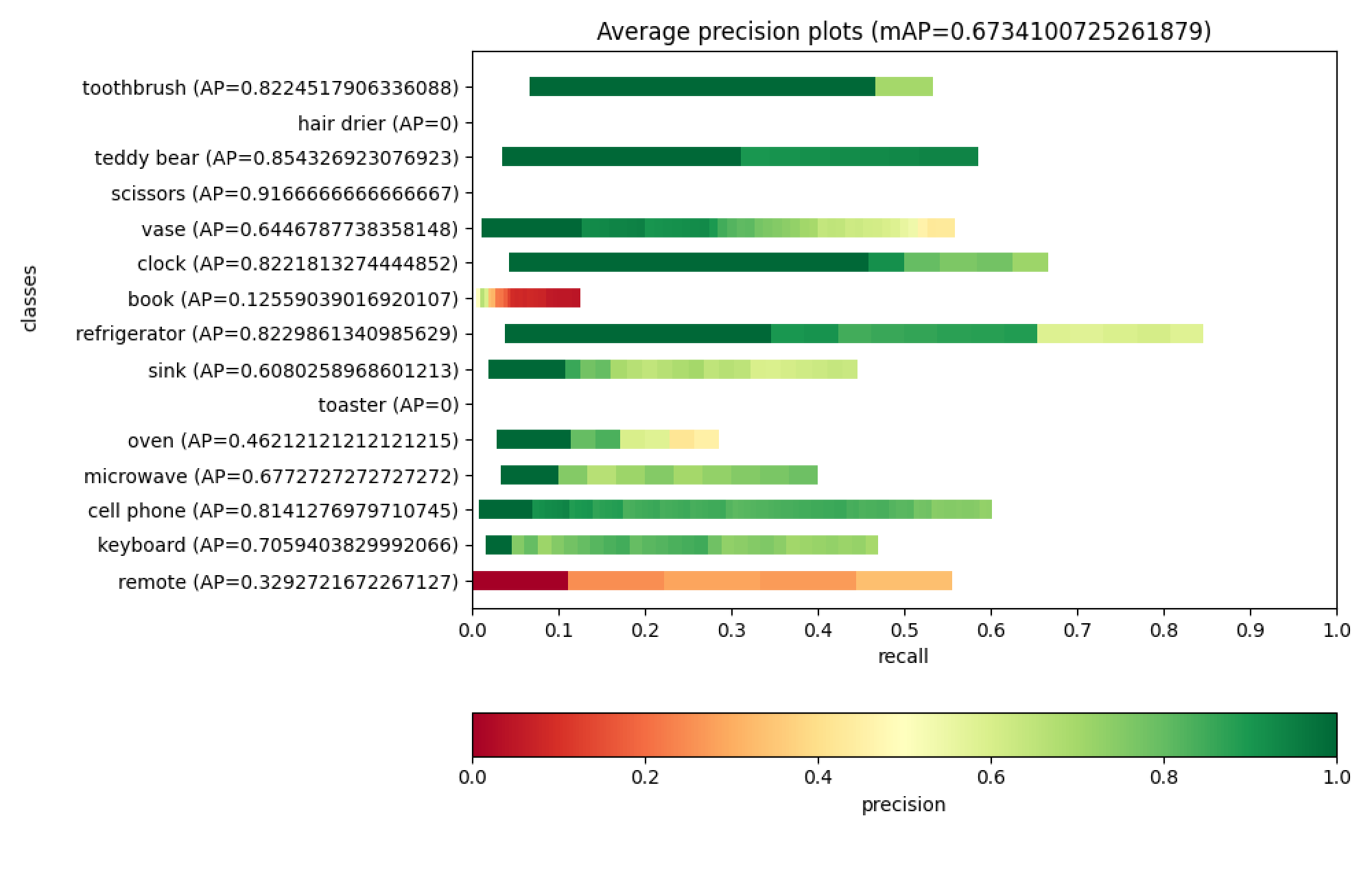
For detection models, Kenning will plot recall-precision curves and per-class average precisions: 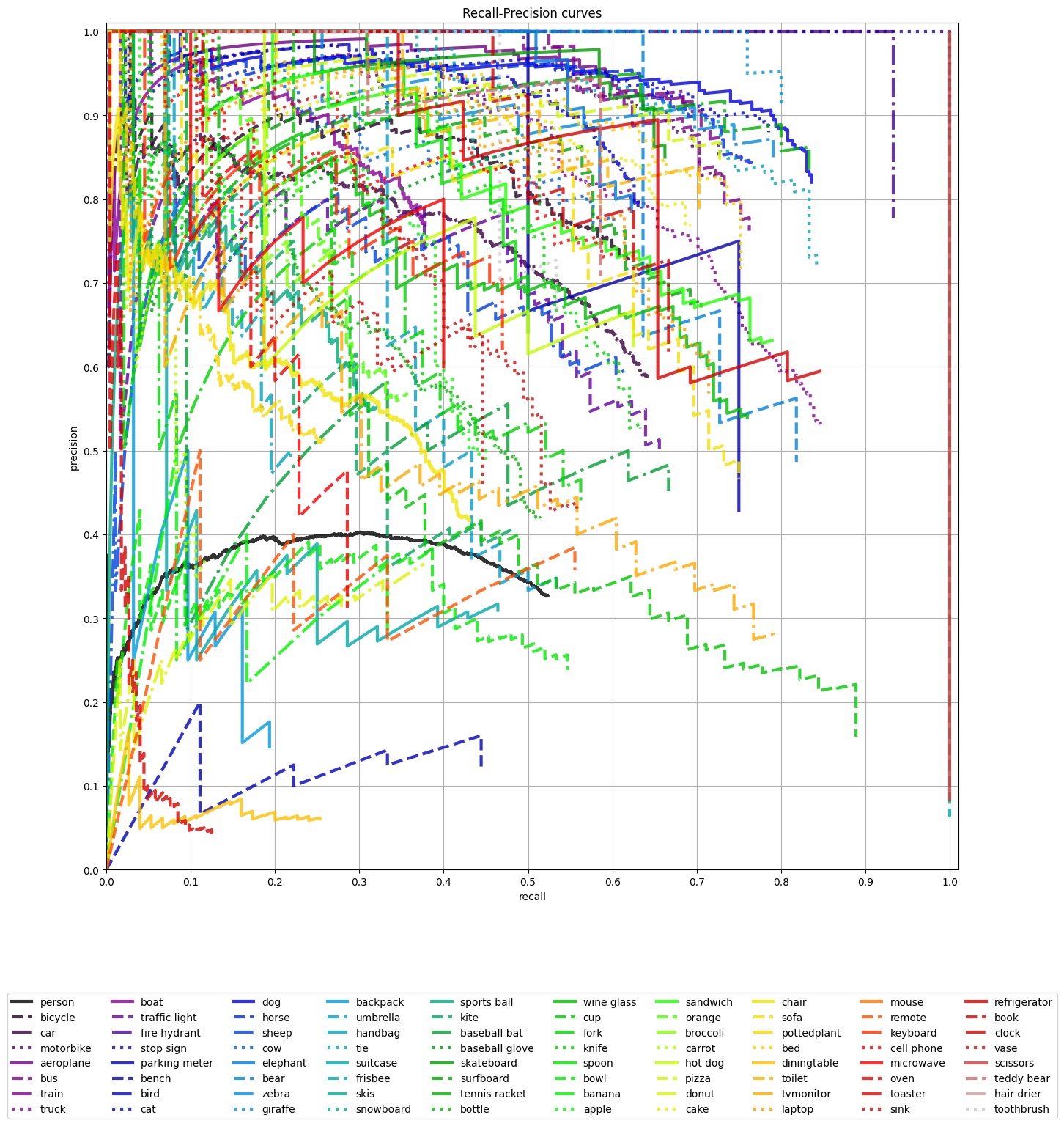
Kenning can also plot the mAP metric change depending on the objectness threshold used to extract the final detection bounding boxes, i.e. in the YOLOv3 deep learning model (which can be used to determine the best threshold for a given model): 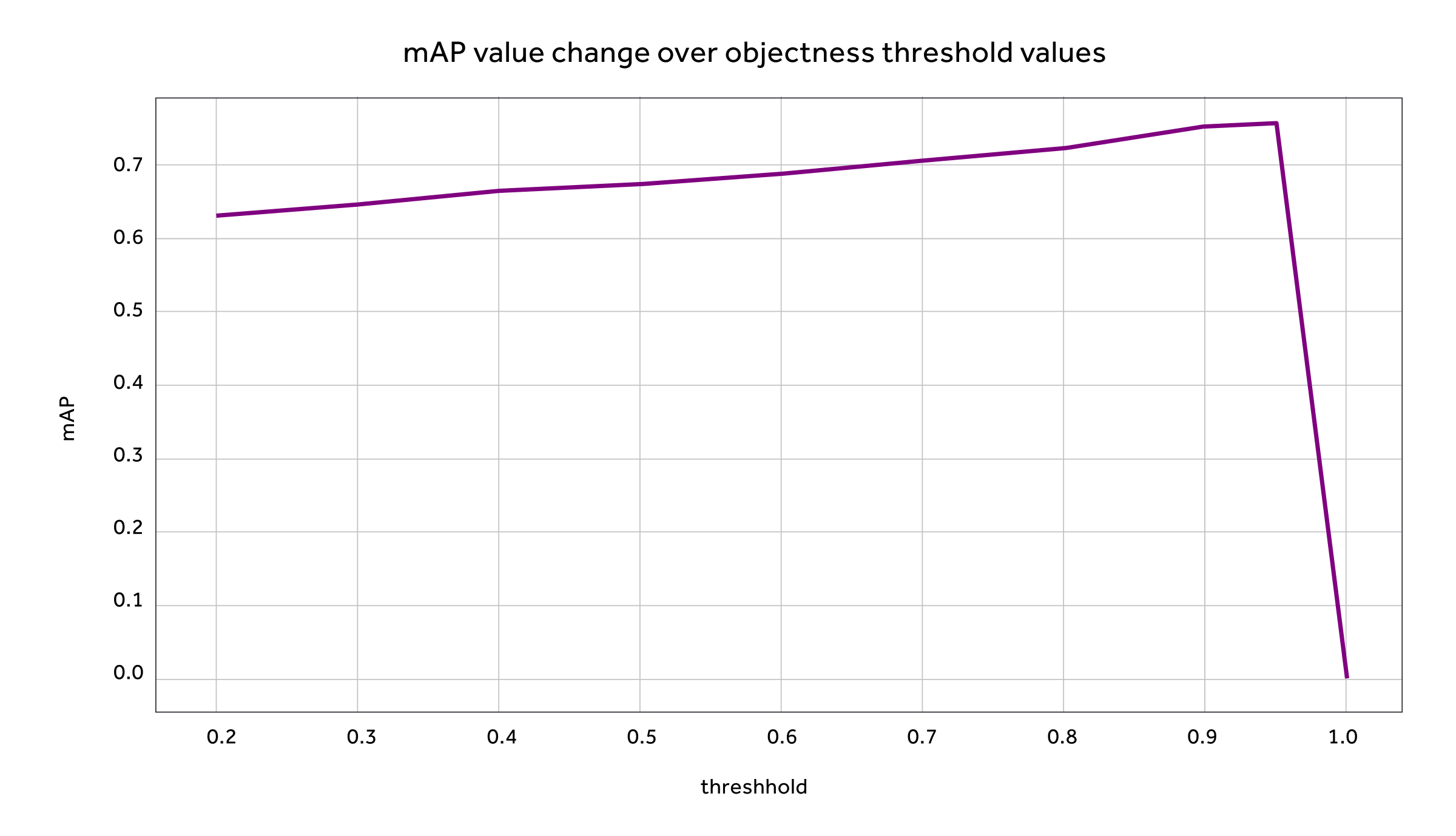
Supported frameworks and targets
Upon release, you should be able to work with a number of models in Kenning, including TensorFlow, PyTorch, Darknet (though only the TVM compiler for now) in the scope of basic operations - specific methods for training or I/O processing will need to be provided.
We’ve also implemented wrappers for Apache TVM, TensorFlow Lite compilers that support input models in TensorFlow, Keras, PyTorch and ONNX format. The Apache TVM compiler wrapper additionally supports darknet models (with respective backends implemented in Python). We’re aiming to have Kenning support multiple protocols (currently implemented Runtimes and Runtime Protocols are written in Python), and, of course, a wide range of AI hardware platforms (from the NVIDIA Jetson family, Coral, the Snapdragon series and more). Any hardware that is supported by the Apache TVM and TensorFlow Lite (ARM processors,GPUs, microcontrollers, TPUs, NPUs, Qualcomm Hexagon DSP, etc.) should be within reach.
To date, the framework has been tested with image classification and object detection deep learning models, and the API for datasets and evaluation currently supports supervised learning. Support for other types of models depends on the chosen learning frameworks and compilers, many of which support various sets of deep learning and even classical machine learning algorithms (such as random forests).
More details
The Kenning framework is now available on GitHub and Antmicro’s Open Source Portal.
Antmicro offers creating flexible, vendor-neutral deep learning deployment flows that can be concisely tested and improved for various edge devices. If you are building an AI-based application, care about portability and cross-platform functionalities, in other words - want to make edge AI deployment agile and vendor-independent in your business - reach out to us at contact@antmicro.com.


