Kenning is Antmicro’s library aiming to simplify the workflow with machine learning applications on edge devices. It is used for testing and deploying ML pipelines on a variety of embedded platforms regardless of the underlying framework. Based on a variety of practical edge AI use cases that we are working with on a daily basis, we have now expanded its functionality to include an environment that will help with development of final applications. Expanding the use case beyond just testing and optimization was achieved by adding Runtime environment - a pipeline allowing to run the tested and optimized models on real-world data and process the results in a multitude of ways.
The Kenning framework’s original goal, as part of the VEDLIoT project, was to optimize and benchmark deep learning applications on edge devices. It also served as an automatic deployment framework for said applications allowing to quickly replicate the setup or tweak the parameters to best suit the use case at hand. The objective was to address the key issue of most machine learning deployment projects - the diversity in frameworks and technologies that, more often than not, may result in compatibility issues later in development. Kenning allows you to keep the flexibility of potentially targeting multiple frameworks and platforms but eventually narrow down on the best performing implementation.
Kenning development workflow
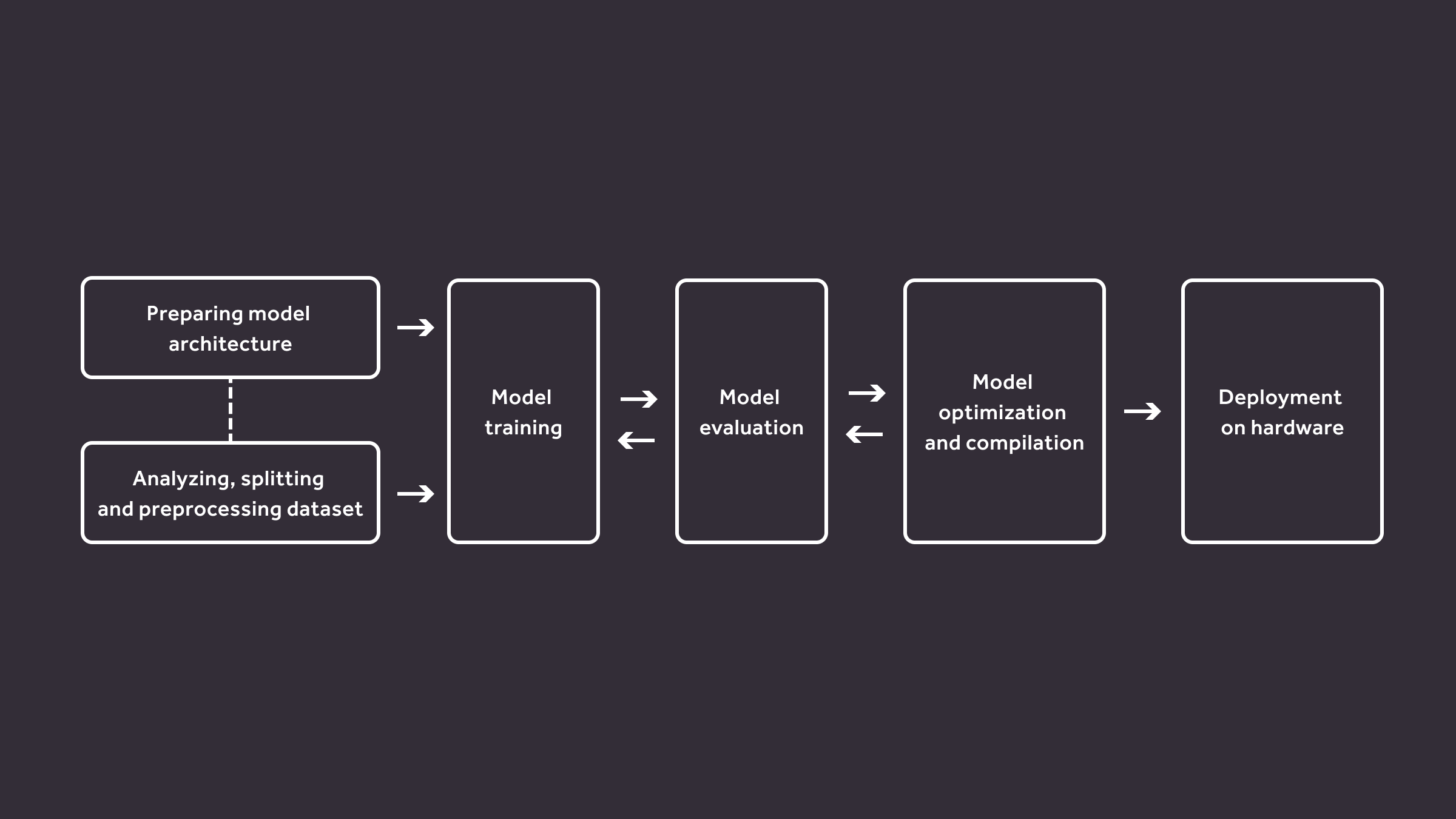
This goal is achieved using modularity - each step of the deployment flow is replaceable to match the required framework or library for each step and replace them if needed at any point. This allows the user to focus on what the application is aimed to do and forget about what specific frameworks are required for each of the steps: training, optimization, compilation and runtime. Every module also includes means to measure time usage and resource utilization at each point and creates reports from the gathered data.
Kenning breaks this deployment flow into 4 submodules:
- Dataset - Wraps the dataset for the model and implements the specific ways to load and preprocess the data from it since datasets rarely save the data or metadata in the same way. It abstracts the specifics from the user and gives simple methods to fetch the data. It performs common input and output preprocessing steps that are shared across models and frameworks, such as loading an image file, converting it to a floating point matrix and normalizing it, or creating one-hot vectors from labels. It is also responsible for evaluating the results given from the Model and producing quality metrics to be later used in reports, such as accuracy, precision, recall of the classification.
- ModelWrapper - It is responsible for loading, training and communicating with the model, as well as implementing the native libraries’ interface to run it. It requires second data processing after the Dataset since many of the models have their own specific output (and quite often also input) format, i.e. YOLO (You Only Look Once) models have the output bounding boxes and classes embedded in the final convolution layers, and need to be computed. ModelWrapper also provides standard methods to serialize the data into a byte stream to be used in Runtimes later.
- ModelCompiler - It wraps the chosen compiler for compilation and optimization specific to the original framework.
- Runtime - Runs the compiled model on the target device. It may be connected with different protocols or be run locally depending on the requirements. It collects the byte stream and passes it to the model and starts the inference process. Then, the results are transmitted for processing and evaluation.
This flow is already proving very helpful in a number of our projects where we need the additional flexibility Kenning provides. However, we soon realized we could do even more with the framework: adapting Kenning to run on real-world data seemed like a fairly straightforward goal. For example, the existing Runtime environments from the deployment pipeline would be easy to adapt for this use case, since they accept any serialized data at the input and do not depend on the Dataset itself at any point. Therefore, the main issue that needed to be addressed was input generation and output handling.
Kenning Runtime
This exact structure was created in the form of a Kenning Runtime environment. It uses existing Runtime procedures and precompiled models to run inference on data gathered from sources other than the Dataset. A DataProvider class is a drop-in replacement for it that contains methods used to fetch the data from whatever source is required - it can be a camera or a video file, a microphone or possibly just a simple sensor. The output that would be normally evaluated by the Dataset is redirected to an OutputCollector, which can process it in whatever fashion is required - for example display it on the user’s screen.
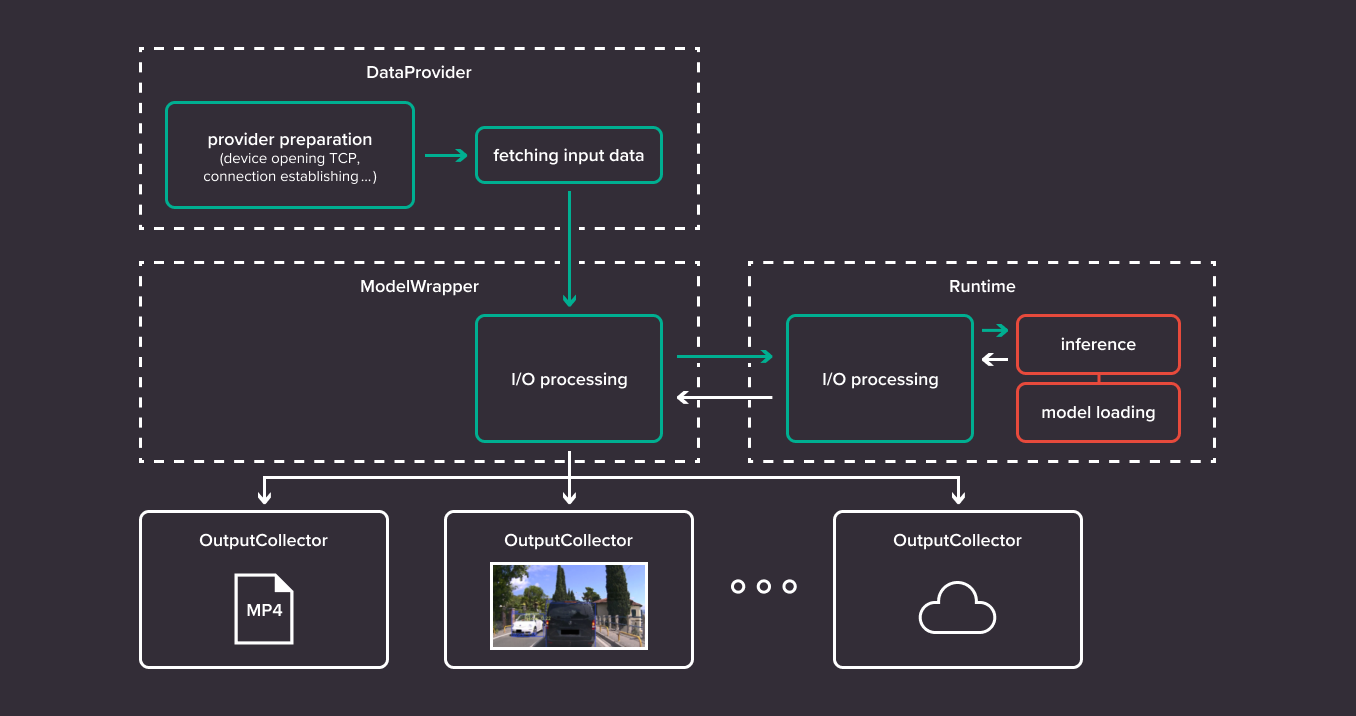
The Kenning runtime flow consists of:
- DataProvider class - a general purpose input source gathering data from non-curated sources, like a camera. It does general preprocessing on data.
- ModelWrapper class - its role is reduced to just I/O processing - tailoring the data to the models’ specific needs and producing understandable data from the output, for example generating bounding box objects.
- Runtime class - its role stays the same as before; it is responsible for running inference.
- OutputCollector class - operates on the preprocessed inputs and model outputs - it can i.e. display the predictions like bounding boxes on the image on screen, save inference results to file, push the data to the cloud. There can be multiple OutputCollectors in the Kenning runtime flow working in parallel for simultaneous processing.
DataProviders are very flexible at their core - their functional requirements are to just pass the data for specific processing by the ModelWrapper later, and the way that this is achieved is arbitrary. This approach allows the framework to be independent not only from the data type (e.g. video), but also from the platform itself. If a specific DataProvider class needs to be implemented to get video data on an obscure device, it is possible as long as the general requirements for the output format are met. As it is basically a superset of the Dataset, it generalizes the specific data type to be from any source.
Currently, we have a single DataProvider that is responsible for handling video from the camera or video file.
In the near future, we intend to implement the following DataProviders:
- TCP-based DataProvider - it will be used to fetch data from a TCP connection
- Microphone DataProvider - it will be used to gather data from a microphone and process it to a consistent audio format like 16-bit PCM WAV (passed down as an array to the audio-based models)
- Directory DataProvider - it will look for files in the filesystem based on the specified pattern, load and preprocess data from the files based on the filetype. The preprocessing of data will be performed using methods from the applicable Datasets and ModelWrappers.
On the other end of the pipeline there are OutputCollectors responsible for handling model output and delivering it to the user or an outside service. Alongside the inference results they also get the unprocessed data frame from the DataProvider in case it is needed. This is useful for example for object detection models where the bounding boxes returned by the model are drawn on a frame of a video and saved as a file or shown to the user.
The flexibility offered by OutputCollectors allows endless configurations of ways to process the data. For this reason the definition of the class is left somewhat abstract, and the only requirement is to have the methods responsible for receiving the data and handling the exit condition of the program - as an endpoint this is the best place to put this necessary feature.
The example OutputCollectors are:
- DetectionVisualizer - handles object detection data and either displays it to the user or saves the video stream as a file. Bounding boxes are drawn on video frames with class names and confidence scores
- NamePrinter - prints the found class names to the terminal. It is used mainly for object classification models.
- TCP OutputCollector (coming soon) - gathers the data and sends it to the TCP client.
Inference Runner
The Inference Runner scenario is the backbone of the runtime mode of operation. It takes a DataProvider, Runtime, ModelWrapper and OutputCollectors classes and runs inference on the target device using the provided implementations.
It checks for closing conditions in the OutputCollectors and DataProvider - the developer may provide a proper closing signal in the above-mentioned input and output blocks (i.e. closing due to end of video or using the close button in a GUI application).
The Inference Runner shows how easy it is to implement all kinds of simple, and even more advanced, use cases in a modular manner. As in the Kenning deployment flow, switching to another target device is a matter of switching the Runtime block to another one, and changes in the software boil down to adding new OutputCollectors and DataProviders.
While Inference Runner can be used on its own as a runtime software, more advanced scripts that e.g. act as a service in a ROS2 node can be created.
Kenning can simplify the workflow with machine learning models and add a quick way to prototype solutions, at the same time being reliable enough to be used as final deployments. Most of the contents can be used as a template - with minor changes it would suit most applications.
Examples of Kennings prototypes and demonstrations:
- Mask R-CNN instance segmentation visualization:

Those images were inferred in full color, however visualizing the masks worked better when the background was grayscale.
- Video demonstration of object detection being performed on a video file
Implementing real-life, portable edge AI pipelines
As can be seen, the Kenning Runtime environment provides a simple, yet effective way to develop machine learning programs with real-life data. In addition, the same framework can be used to optimize and benchmark the model with minimal effort. Handling of most data types can be added via the DataProvider and OutputCollector interfaces along with a multitude of ways to process the computation results. The requirements for each new class have been made such that it is as effortless as possible to implement new functionalities.
If you are looking to develop a new device which runs AI on the edge, utilizing anything from an embedded GPU, FPGA, DSP or AI accelerator, reach out to us at contact@antmicro.com and see how we can help; perhaps the flexibility of the Kenning framework will be applicable to your use case as well.


