AI processing of complex data such as images, text, and sound can be used in a factory environment to vastly simplify tasks like classification, counting, tracking, quality assurance, or anomaly detection. Making large-scale, on-the-spot processing on a production line feasible requires high parallelization, efficient resource management and low-latency AI processing.
In this blog note, we will take a look at one of Antmicro’s customer projects, aimed at introducing AI capabilities to an existing factory setup using NVIDIA’s Jetson AGX Xavier, and use it as an example to describe how such projects can benefit from employing Kenning, Antmicro’s framework for creating deployment flows and runtimes for Deep Neural Network applications on various target hardware along with its quickly expanding toolkit for DNN optimization and application development.

Introducing AI to an industrial environment
In the customer project in question, our work revolved around processing X-Ray images, each showing hundreds of packages containing individual items, in order to sort the products into their respective categories and determine whether they comply with quality norms enforced by the customer. The classifier was to be used on an already existing, large-scale sorting machine.
In order for the upgrade to be efficient and cost-effective, we set out not to introduce any significant modifications to the structure or software of the sorting machine and made sure that the new features did not disrupt the existing workflow. Another goal was to make the solution easy to extend with features like elaborate image preprocessing (to remove X-Ray artifacts, noises, and reflections coming from the packaging and cut irrelevant content from the image) involving filters, thresholding, normalization routines, segmentation of objects and optimizing the selected masks for irrelevant values or features. The customer also needed the capability to implement more models for package classification and other uses and access these processing pipeline extensibility features via a simple UI.
Selected hardware
In order to seamlessly add AI capabilities to the sorting machine as necessary, we used NVIDIA’s Jetson AGX Xavier, which could be connected to the rest of the machinery via Ethernet, requiring only minor modifications to the machine’s software. The heavy processing was delegated to the Xavier module, and the predictions were relayed back using a TCP-based protocol. With 32GB of RAM, 512 Volta CUDA cores, 64 Tensor Cores, dedicated DLAs, and an 8-core CPU, handling large batches of data with multiple models was definitely feasible, but ambitions in terms of latency, parallelism, and results were high, resulting in a very interesting and iterative optimization project.
Now, the AI platform landscape offers even more computing power, not in the least with the next-gen NVIDIA Jetson Orin series we have been describing in our recent blog notes - and many customer projects like this one are in the process of migrating to the new SoM family with Antmicro’s help, using the open source Jetson Orin Baseboard. Kenning itself is also a useful tool in the migration process, given its features that help track and compare performance.
Model optimization
Optimizing computationally and memory-demanding algorithms such as DNN for the use case and platform at hand is typically the key element for enabling breakthrough applications in emerging fields. While there are a lot of impressive PC-based AI pipelines and general-purpose edge demos to be found online, they typically don’t focus on resource usage, ease of integration into a bigger system, or robustness for specialized tasks. Kenning, with its special focus on optimization for the edge, productivity, and integration with common tools such as Yocto, helps our customers innovate faster, with more transparency over the elements of the flow and their contribution to overall processing time.
When it comes to NVIDIA Jetson platforms, it is important to point out that achieving optimal results is a combination of many factors and not a single-axis dial. To start with, most NVIDIA platforms can benefit from quantization - a process where weights and activations are stored in the form of lower-precision integers instead of standard 32-bit floating-point values. Computing 8-bit weights and converting activations to 8-bit values (accumulators are 32-bit) can significantly reduce memory usage and processing time with only a slight decrease in quality. In addition, starting with the Volta architecture, NVIDIA’s platforms have Tensor Cores able to compute matrix multiplications of 16-bit floating point or 8-bit integer weights at outstanding speeds. With 16-bit floating point weights and activations, we can still get an over 1.5x processing speed increase and a model almost 2x smaller without sacrifices in prediction quality. When we combine quantization with batching, we can expect further significant speed increases.
Below, you can see how processing time changes depending on the batch size and weight/activation values:


Many existing frameworks use their own toolkits for optimizing DNNs that perform such operations as quantization, pruning, clustering, etc. Usually, however, support for various optimization techniques differs, e.g., various algorithms can be used, not all techniques are supported in all frameworks, or support for a given network operator is limited. When working with Kenning, you are not bound to just the tools that a particular framework offers, as you can seamlessly jump from one framework to another, which allows you to tinker with your model. Then, you can test the results directly on a hardware platform while tracing the quality and speed of your solutions.
In the end, such an optimized, compiled model can be used during runtime once its speed, size, and quality are satisfactory. What is more, a model can be optimized to process multiple images at once, as quickly as possible, since single image processing does not usually utilize the GPU fully and some of DNN operations are optimized specifically for large batch processing. This opens up an opportunity to process multiple instances of data in parallel in a single batch. Usually, provided the number of parallelly processed images is not exceedingly large, we can achieve a boost in speed that allows for hundreds of images to be processed within a second.
Fine-tuning with the Kenning toolkit
In parallel with model optimization, we needed to implement the runtime. For prototyping purposes, we are now able to use KenningFlow features that allow us to involve multiple input sources as well as multiple processing blocks and models. This feature is described in more detail in one of our previous blog notes.
Thanks to its modular structure and its implementation in Python, Kenning makes for a simple and convenient software prototyping and construction tool. Now we have taken further advantage of these properties and lowered Kenning’s entry-level by introducing Pipeline Manager, a graphical tool that helps visualize, edit, validate, and run data flows in Kenning without the user ever needing to touch actual code.
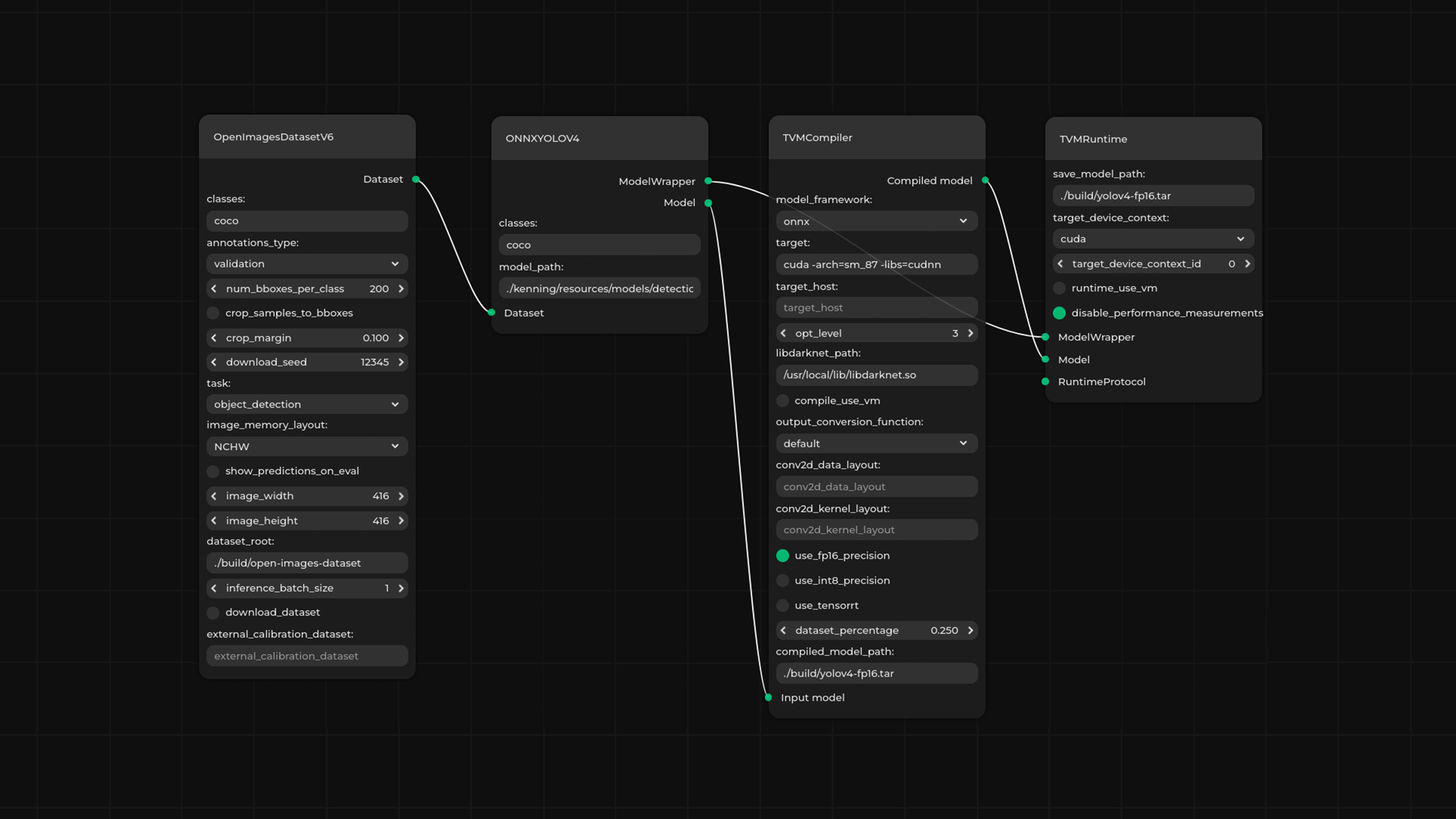
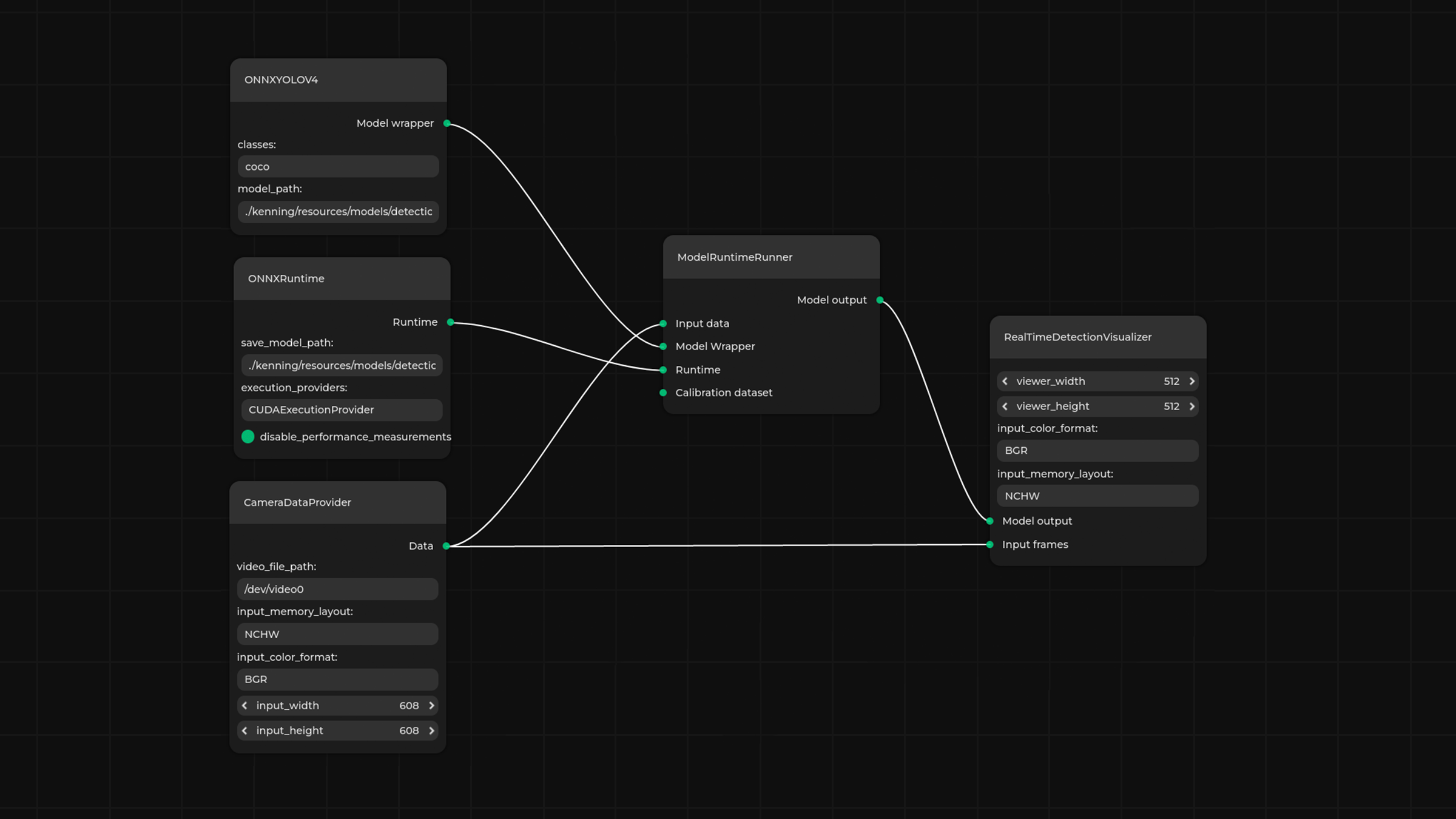
Once a project’s prototyping stage is completed, we can move on to a fine-tuning stage dedicated to our particular use case, e.g., implementing a C++ runtime. In the case of this particular project, we implemented the final runtime software in C++, with OpenCV, utilizing multithreading, CUDA, and TensorRT. OpenCV allowed us to significantly speed up the preprocessing stage since it provides many algorithms implemented for both CPU and CUDA runtimes.
As for streamlining work with CPU and CUDA, we also took advantage of a feature that members of the Jetson family offer, namely memory shared directly between the CPU and the GPU/CUDA. This feature, when carefully handled, makes it possible to avoid unnecessary copying of large amounts of image data and to seamlessly jump between CPU and CUDA processing, reducing memory utilization and processing time in the process.
Next, we introduced latency hiding through:
- Parallel multiple image preprocessing
- Parallel model preprocessing and inference
- Parallel data collection and sorting machine communication
This way, we were able to properly saturate Jetson AGX Xavier’s computational power and fit processing stages in short enough time to avoid slowing down the rest of the machine’s flow.
Before connecting the Jetson AGX Xavier to the physical sorting machine, we simulated the communication between the two using a mock application that we implemented in the same language as the sorting machine software (C#) to ease the process of integration for the client and to have a unified and clear means of communication.
Creating a hardened Board Support Package
Once the initial proof of concept was successfully tested along with the target hardware, we worked on improving the application alongside implementing a dedicated hardened system for deployment.
At Antmicro, we always aim towards creating reproducible, hardened support packages for our boards and projects to significantly improve robustness, reliability and traceability of our solutions. As described in our blog note about Over-The-Air updates, we create systems that contain redundant system images that serve as a failsafe in case of system failure (or update failure), add mechanisms for updating systems remotely, and we use the read-only filesystem as default to further prevent data failure. On top of this, we also supply our customers with a CI infrastructure that builds systems and software from the source in a clean and reproducible environment, providing them with fully traceable deployment.
Develop comprehensive industrial AI solutions with Kenning and Antmicro
Whether you need to design an AI-capable machine for your industrial use case from the ground up or adapt your existing production line elements to gain AI functionalities like the ones described above, Antmicro can help you choose a platform most efficient for your use case, develop all necessary hardware and secure software optimized and prototyped using Kenning and its tools, as well as implement base systems, and CI responsible for testing and update deployment.
If you would like to discuss how you can take advantage of state-of-the-art AI solutions in your industry, do not hesitate to contact us at


