Kenning helps develop real-world Machine Learning solutions for ARM and RISC-V platforms such as NVIDIA Jetson AGX Orin, Google Coral or HiFive Unmatched by seamlessly interconnecting different underlying optimization and deployment frameworks and creating rich reports on model quality and performance, like in the recently described industrial use case. The latest developments extend Kenning’s applicability to two new domains, adding bare-metal runtimes for non-Linux targets and integration with Renode for simulation-based machine learning RISC-V silicon co-development.
RISC-V based machine learning ASIC co-development
Thanks to their increasing computational capabilities and the open ISA’ s ability to tailor silicon to specific use cases with vector and custom extensions, RISC-V based microcontroller devices are an especially interesting target for Machine Learning workflows in low-power applications. Antmicro’s work with a variety of ML-focused silicon development cases such as Google’s AmbiML project, has allowed us to extend our open source simulation framework, Renode with support for the RISC-V V spec and flexible interfaces for adding custom extensions, as well as features for gathering extensive information on the execution of ML workloads. Integration with Kenning - focusing on ML benchmarking and optimization - is a logical next step.
In order to use Kenning to harness the potential of constrained platforms for ML acceleration, we needed to implement a bare-metal runtime in C, able to run models compiled using the IREE (Intermediate Representation Execution Environment) library. Based on this example, we will show how Kenning and Renode can be used in tandem to develop and test ML flows without hardware in the loop.
This integration of Kenning and Renode allows us to get full insight into model execution and AI accelerator utilization in a fully automated, reproducible and consistent manner, bringing CI and scripting benefits to development of models, optimization libraries and AI accelerators.

IREE framework and its integration with Kenning
Google’s IREE framework, which recently became part of the OpenXLA ecosystem, is a Multi-Level Intermediate Representation-based (MLIR) end-to-end compiler and runtime for machine learning models. It can take models from popular frameworks such as PyTorch, TensorFlow, or JAX, convert them from graph representation into a set of asynchronous schedules optimized for specific platforms (ARM, x86, RISC-V, GPU via Vulkan/CUDA), and compile them into highly efficient bare-metal runtimes, allowing complete control over memory management. IREE also provides runtime sources and libraries for interfacing with the compiled model on platforms such as Linux, Android, iOS, Windows, and even without an OS.
Kenning now includes an IREECompiler that uses IREE to compile the model and an IREERuntime class that runs the compiled model using the IREE runtime (described further below). It allows users to quickly get started with IREE optimization testing, and to quickly compare the runtime performance to other frameworks supporting the same target platform to find the best-performing solution. In addition, this search for the best-performing model can be automated with Grid Optimizer described in a previous blog note.
Bare-metal runtime for Kenning
To enable the Springbok/IREE platform and use case, we needed to add support for bare-metal runtimes in Kenning, which is included in the kenning-bare-metal-iree-runtime repository that implements:
- The bare-metal Runtime for Kenning in C, currently using the IREE runtime to run the model, and configured for running on the Springbok platform
- A RuntimeProtocol for Kenning in C, allowing the Kenning Python API to deploy and test the model to communicate with the Springbok platform via UART to send the model, exchange inputs and predictions and pass additional data required for benchmarking
On Kenning’s side, we implemented a UARTProtocol that communicates with the platform. The minimal Kenning scenario for compiling and testing models on the Springbok platform with the bare-metal IREE runtime and UART communication looks as follows:
{
"dataset": {
"type": "kenning.datasets.magic_wand_dataset.MagicWandDataset",
"parameters": {
"dataset_root": "./build/magic-wand-dataset",
"download_dataset": true
}
},
"model_wrapper": {
"type": "kenning.modelwrappers.classification.tflite_magic_wand.MagicWandModelWrapper",
"parameters": {
"model_path": "./kenning/resources/models/classification/magic_wand.h5"
}
},
"optimizers": [
{
"type": "kenning.compilers.iree.IREECompiler",
"parameters": {
"compiled_model_path": "./build/tflite-magic-wand.vmfb",
"backend": "llvm-cpu",
"model_framework": "keras",
"compiler_args": [
"iree-llvm-debug-symbols=false",
"iree-vm-bytecode-module-strip-source-map=true",
"iree-vm-emit-polyglot-zip=false",
"iree-llvm-target-triple=riscv32-pc-linux-elf",
"iree-llvm-target-cpu=generic-rv32",
"iree-llvm-target-cpu-features=+m,+f,+zvl512b,+zve32x",
"iree-llvm-target-abi=ilp32"
]
}
}
],
"runtime": {
"type": "kenning.runtimes.iree.IREERuntime",
"parameters": {
"driver": "local-task"
}
},
"runtime_protocol": {
"type": "kenning.runtimeprotocols.uart.UARTProtocol",
"parameters": {
"port": "/tmp/uart",
"baudrate": 115200,
"endianness": "little"
}
}
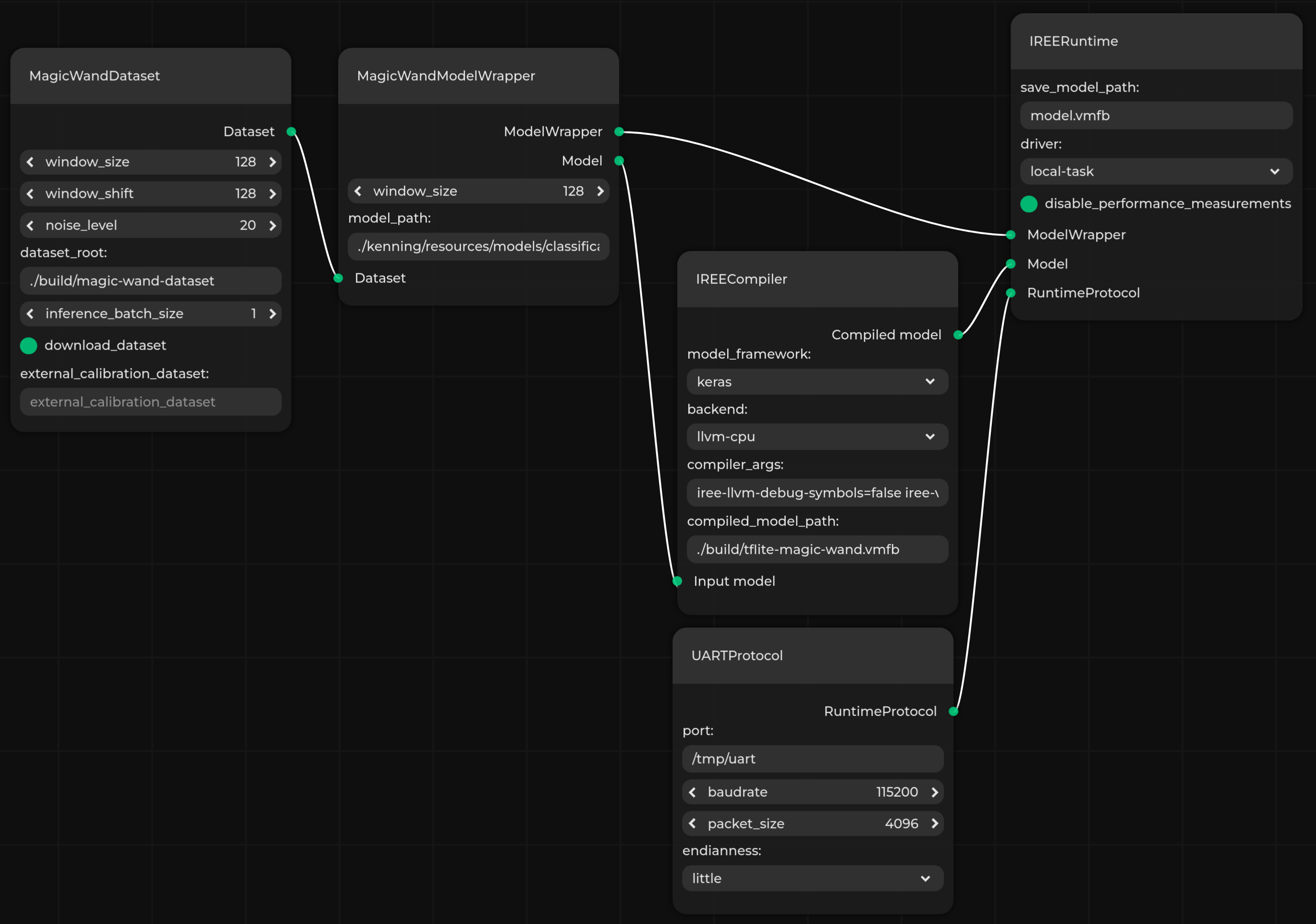
}The model tested here classifies gestures based on accelerometer and gyroscope data (Magic Wand Dataset). The model is trained in TensorFlow and saved as magic_wand.h5. It is later optimized and compiled with IREECompiler using LLVM targeting a RISC-V processor, with V Extensions specified in iree-llvm-target-cpu-features. The model is compiled to the VMFB (Virtual Machine Flat Buffer) format, a compact binary specifying the model runtime for IREERuntime running on bare metal. The IREERuntime class provides additional data preprocessing before sending it to the device, but the actual runtime happens on the simulated Springbok accelerator.
A UART with 115200 baud rate on the /tmp/uart port is used as the communication protocol. Compared to other RuntimeProtocol implementations available in Kenning, this one does not send metrics or model metadata (such as information about inputs and outputs) in JSON format, but creates C-like structures that can be read or created by C runtime without any parsing, simplifying the entire communication process.
JSON files like this one can also be visualized, validated, run, and even designed using the browser-based, open source Pipeline Manager GUI tool, which you can read more about in one of the previous Antmicro blog notes. Below you can see how this particular flow is represented in a graph form.
Springbok simulation in Renode
As described in an article published on the Google Open Source Blog as well as detailed in a presentation at RISC-V Week Europe 2022, our collaboration with Google involved building a Renode simulation platform for Springbok, a RISC-V-based accelerator that uses V extensions to efficiently handle heavy AI workloads. As its ML compiler and runtime library, Springbok employs IREE, which in turn utilizes LLVM to compile the model for Springbok using RISC-V Vector Extensions to reduce the number of instructions needed to compute heavy algebra operations.
Running AI pipelines on an accelerator simulated in Renode in such use cases drastically reduces the development cycle, eliminating the need for waiting for hardware or relying solely on hardware emulation, simplifying the unlimited sharing of fully reproducible development environments, introducing the ability to use CI, and granting comprehensive insight into the entire platform.
If you would like to test the performance of IREE itself on a simulated Springbok core on your local machine, take a look at the demo in the iree-rv32-springbok repository, which provides the necessary libraries and tools to compile the model and deploy it in a simulated environment. The application running on Springbok is bare metal, implemented in C.
End-to-end testing framework for AI development
The ability to fully simulate a ML-capable target with RISC-V Vector instructions is actually good for Kenning itself as well. A reproducible environment without the need for physical hardware allows us to easily demonstrate and comprehensively test end-to-end solutions in Continuous Integration pipelines, providing unique automation for the entire edge AI development flow.
What is more, we have added the ability to collect metrics from Renode in Kenning, creating even richer reports that show the exact instructions used by the runtime, whether or not the accelerator was used as expected, and if more processing power can be extracted. With these performance metrics paired with quality checks in the loop, we can reliably track the quality of predictions and hardware utilization in a fully traceable, scriptable manner, using CI. This can significantly improve the developer experience and be especially powerful when working on tasks such as:
Model optimization - in an AI-enabled product creation scenario, we can create a CI pipeline and a development workflow that provides precise information on how the model is performing after applying optimizations with Kenning and its underlying frameworks, and the simulated AI accelerator utilization.
Optimization and compilation framework implementation - such end-to-end tests can improve development of various optimization frameworks, giving us more information on how models perform with different instructions, quantization techniques, approximation functions, and runtime schedules.
Developing new AI accelerators - Renode allows us to either create simulation models for an accelerator, or co-simulate HDL design with Verilator, with features described in more detail in numerous Antmicro blog notes, including creating tailored AI acceleration instructions in RISC-V with Custom Function Units. Because of that, it is possible to create a powerful platform for advanced and automated development of AI accelerators, where designs can be tested against actual models in a reproducible manner, providing easy-to-follow, comprehensive reports for every change in design, driver or deployment framework.
Running IREE in Kenning on your local machine
The full demo for testing a model with Kenning and Renode on the Springbok platform is described in detail in the README for the bare metal runtime - please refer to it for up-to-date instructions.
The demo provided in the README begins with a Springbok simulation starting in Renode and running the bare metal application, and the Kenning inference tester starting in parallel. The Kenning process then prepares the dataset and compiles the model using IREE with RISC-V V extensions before connecting with the simulated Springbok device via UART on the /tmp/uart port and sending the model in VMFB format to Springbok, along with the model’s input and output specification. The bare-metal runtime subsequently loads the model and prepares for inference and the Kenning process sends test inputs from the dataset, receives predictions, collects performance metrics, and evaluates the model.
With the simulation over, Renode generates files with performance information, and the Kenning process creates a JSON file containing final measurements, based on which Kenning’s report renderer creates a final report in Markdown.

Develop bare-metal AI runtime with Kenning
With Kenning, you can use IREE along with other optimization and compilation frameworks to build, test, and optimize your AI models and workflows on different platforms, including bare-metal, and use the traceable, easy-to-analyze reports generated by the system to iteratively improve model runtimes and performance on your target hardware.
Thanks to the recently announced ARMv8-A and 64-bit peripheral support in Renode and upcoming ARMv8-R support, the capabilities of the Renode-Kenning integration can be expanded to a wide array of AI-capable platforms.
If you would like to explore the possibilities of adapting and customizing Kenning for your specific use case and accelerate development and testing with simulation in Renode, don’t hesitate to contact us at contact@antmicro.com. We can help you implement state-of-the-art AI solutions, develop the necessary hardware and software, and provide testing and update mechanisms to ensure optimal performance and efficiency for your AI-driven applications.


